NINETY DAYS
-
Or they select very carefully upon the calculation:
it's a difference if you count ALL services working and ANY disruption, even that of a single service/server as fail, or whether you count a single server failure against the total number.If you have 100 (virtual) servers you can keep one server swicthed off ALL THE TIME (0% individual availability) and still have 99% availability overall.
@vampirdaddy @SecurityWriter @0xabad1dea I once worked at a company I liked that said "anyone promising 100% uptime is lying"
They got bought out and ruined by a company that said "100% UPTIME*" on the wall
and in tiny tiny writing "*core network uptime" way down in small print in the basement
-
@vampirdaddy @SecurityWriter @0xabad1dea I once worked at a company I liked that said "anyone promising 100% uptime is lying"
They got bought out and ruined by a company that said "100% UPTIME*" on the wall
and in tiny tiny writing "*core network uptime" way down in small print in the basement
@vampirdaddy @SecurityWriter @0xabad1dea Because, technically, they had a very large core network and they'd had a COMPLETE nationwide network outage.
Of course this bullshit did not fly anytime they had a LOCAL outage.
-
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea a incident a day keeps the customers away
-
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea@infosec.exchange 9.9999% is also five nines
-
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea Micro$oft turned MicroSlop
-
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea@infosec.exchange Why do people still put their code into that crap site?
-
@0xabad1dea@infosec.exchange mfw the server that lives in my basement has better uptime than a trillion dollar company
@eri @0xabad1dea I said this about the server under my desk on a residential connection on reddit and people got super mad that I'm comparing my shitty server serving 5 people to github serving 8437823748932789432 people except that I put zero effort into running my server and I don't earn money off of that lmao
-
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea They're so close to achieving zero nines.
How do you even manage 90% uptime over 90 days?? 9 full days of downtime??
My homelab has been subjected to frequent power outages due to the house getting a bunch of electrical work & renovations done, and I've still managed at least 97%.
-
@0xabad1dea you can get more 9s of uptime is the first number is an 8
@aeri @0xabad1dea Creative decimal placement can make a big difference too. Move it one place to the left and there’s no need to bring an “8” into play. Sure, we need to redefine the “high” in “high availability” but I’m up for it if everyone else is. #HighAvailability
-
@eri @0xabad1dea I said this about the server under my desk on a residential connection on reddit and people got super mad that I'm comparing my shitty server serving 5 people to github serving 8437823748932789432 people except that I put zero effort into running my server and I don't earn money off of that lmao
@eri @0xabad1dea oh this includes that I thought my geckos got into it and I shut it down, maybe they also have geckos at the data center
-
@0xabad1dea They're so close to achieving zero nines.
How do you even manage 90% uptime over 90 days?? 9 full days of downtime??
My homelab has been subjected to frequent power outages due to the house getting a bunch of electrical work & renovations done, and I've still managed at least 97%.
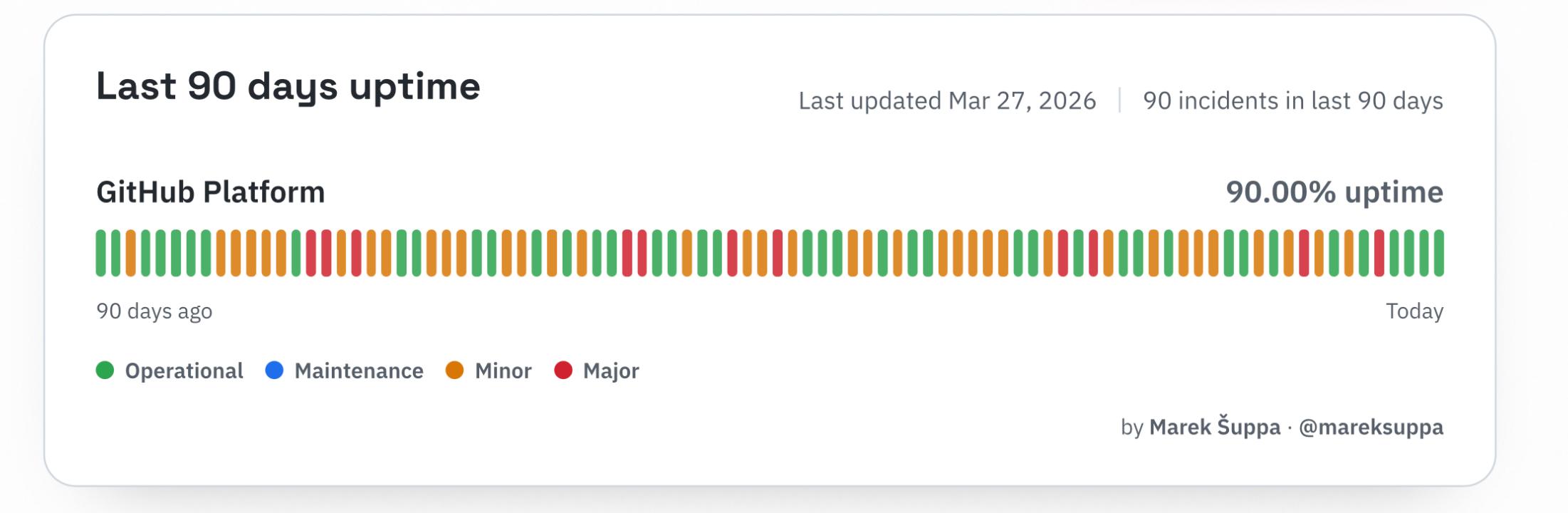
@Misofist this graph (which is an independent third party tracker) is calculated by overlaying any detected issues from ten separate sub-systems of github on one timeline. Red bars are when any one of those ten subsystems has a critical failure, yellow is when any one of them has observable issues.
So it's not quite as extreme as 10% of the time just being completely, utterly dead. But still much worse, these last few months, than usual
-
@Misofist this graph (which is an independent third party tracker) is calculated by overlaying any detected issues from ten separate sub-systems of github on one timeline. Red bars are when any one of those ten subsystems has a critical failure, yellow is when any one of them has observable issues.
So it's not quite as extreme as 10% of the time just being completely, utterly dead. But still much worse, these last few months, than usual
@0xabad1dea Yeah so it's more like 10% degraded service rather than 10% downtime.
Still, what the actual fuck.
-
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea It was a typo, they meant 5 8s and look, they exceeded their goal!
-
@0xabad1dea i bet i know what's going on here
@erikarn @0xabad1dea synthetic text extrusion doesn't actually make great software.
-
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea Didn't know they meant .99999%.
-
@0xabad1dea they're right there, idk what your problem is
@emily @0xabad1dea I don't know if I should make a Plan 9 or a Touhou reference, so https://analognowhere.com/_/lxhtmg/
-
@slembcke to confirm what someone else said while I was asleep, it’s an independent third party tracker called the “missing” github status page. https://mrshu.github.io/github-statuses/
they track ten subsystems separately, which are each in the 96% to 99.9% range, then overlay all those incidents on the same timeline to arrive at 90% overall.
I do not have any particular stance on whether github’s own tracker or this third party one is more fair and accurate, beyond “90-90-90 is hilarious” and observing only one of them has a contractual stake in possibly sometimes downplaying issues a little bit.
@0xabad1dea @slembcke if each subsystem is crucial for github to work, you multiply those uptimes and get 90.
If the subsystems are independent then can't do that.
If the CI system is down, you can't say github is down.
I would then merge the timelines and get some metric "how long has there been no issue at all".
That can be very low and the website is still fine. -
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea Do I just imagine hearing voices from the engine room – or do you hear them as well?
- Of course you're right, I should not have shut down that service…
Not that one either you dumb §#%!
- Oh my, of course not!
Hey, do not… AAAAAA!
-
NINETY DAYS
NINETY INCIDENTS
NINETY PERCENT
YOU PAID FOR ALL FIVE NINES BUT YOU’LL ONLY NEED THE EDGE
@0xabad1dea GitHub used to be genuinely stable. Also I haven’t noticed a single useful new feature in years.
Question is, is it a general Microsoft/firing people problem. Or is it AI?
-
@0xabad1dea GitHub used to be genuinely stable. Also I haven’t noticed a single useful new feature in years.
Question is, is it a general Microsoft/firing people problem. Or is it AI?
@yon bit of column A, bit of column B, bit of column "global hardware crisis" due to column B