i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
-
this isn't satire, this is real research published by IEEE/ACM
@whitequark @danlyke so … by "reformatted" I assume you mean aesthetically tidied up, with no change in functionality required?
If I got that right: wtf?
-
i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
the "ideal" (their choice of words) case is 64.2%
@whitequark compare and contrast the Extreme Programming philosophy, in which a code change doesn't count as "refactoring" unless all observable behavior is identical
-
@whitequark @danlyke so … by "reformatted" I assume you mean aesthetically tidied up, with no change in functionality required?
If I got that right: wtf?
-
i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
the "ideal" (their choice of words) case is 64.2%
@whitequark And this is how research money is lit on fire, I guess. Why else conduct research into ML for a task that has had obvious, deterministic, efficient and well-tested solutions for decades?
-
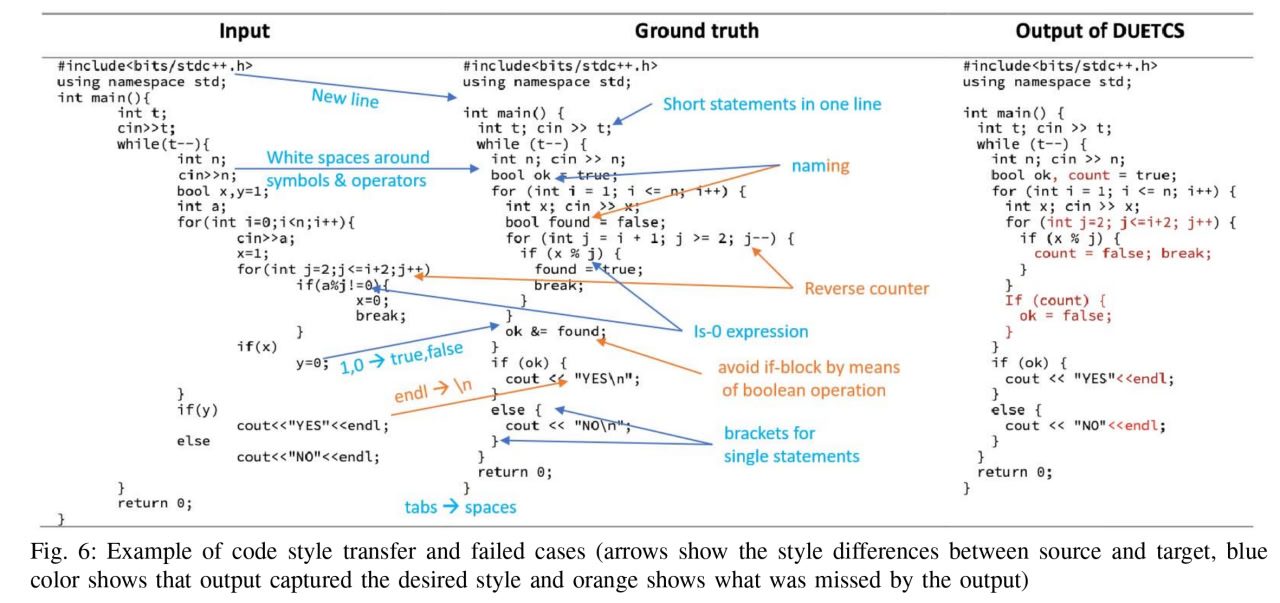
@porglezomp you'll love Fig. 6
@whitequark @porglezomp This looks like it could join the current crop of "DLSS5 off/DLSS5 on" memes.
-
@whitequark compare and contrast the Extreme Programming philosophy, in which a code change doesn't count as "refactoring" unless all observable behavior is identical
@ireneista TIL that my philosophy is the same as the Extreme Programming philosophy
-
@whitequark compare and contrast the Extreme Programming philosophy, in which a code change doesn't count as "refactoring" unless all observable behavior is identical
@ireneista i like how it starts with this (left) and ends with "here is a variable we think would be good here. Do you like this" (right)

-
@ireneista i like how it starts with this (left) and ends with "here is a variable we think would be good here. Do you like this" (right)
@ireneista starting with "gotofail bad" and ending with making the problem significantly worse, apparently without ever reflecting on this
-
@whitequark And this is how research money is lit on fire, I guess. Why else conduct research into ML for a task that has had obvious, deterministic, efficient and well-tested solutions for decades?
@lu_leipzig I actually really don't like formatters like
blackorrustfmtwhich is why I'm collaborating on research into doing it with ML, but there are ways to do it that never produce a different AST -
i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
the "ideal" (their choice of words) case is 64.2%
@whitequark so excited about astral being acquired...
-
i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
the "ideal" (their choice of words) case is 64.2%
@whitequark That's it, these people lose their computer privileges until they take some undergraduate CS theory classes.
-
@lu_leipzig I actually really don't like formatters like
blackorrustfmtwhich is why I'm collaborating on research into doing it with ML, but there are ways to do it that never produce a different AST@whitequark oh, interesting, what do you not like about them? I could imagine a ML model would do a decent job deciding between n equivalent deterministically produced ASTs that vary e.g. w.r.t. indentation on multi-line definitions/calls.
-
@whitequark That's it, these people lose their computer privileges until they take some undergraduate CS theory classes.
@theorangetheme both authors are currently full professors i believe
-
@ireneista starting with "gotofail bad" and ending with making the problem significantly worse, apparently without ever reflecting on this
@whitequark because "the thing we're promoting is incredibly dangerous, and not in fun ways" is not really the thing anyone wants to be cited for
-
@whitequark oh, interesting, what do you not like about them? I could imagine a ML model would do a decent job deciding between n equivalent deterministically produced ASTs that vary e.g. w.r.t. indentation on multi-line definitions/calls.
@lu_leipzig I view code as art and so any tool that puts determinism strictly above aesthetics is a net negative to my craft
-
@lu_leipzig I actually really don't like formatters like
blackorrustfmtwhich is why I'm collaborating on research into doing it with ML, but there are ways to do it that never produce a different ASTEven if the AST is the same, might a sufficiently bad format mislead humans reading the resulting code?
I'm reminded of the Obfuscated C Contest…
-
i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
the "ideal" (their choice of words) case is 64.2%
@whitequark@social.treehouse.systems I didn't know the ideal number for code to behave differently was over 30% of the time!
Then again, I like and don't mind working with legacy code and systems so I personally tend to wonder "why even redo a working thing" -
@whitequark @porglezomp I'm spitting out my drink at j++ → j--. Holy shit.
@xgranade
I think the right is the output from running the model on the right code (center being the "desired output"). So it's not changing the semantics of the loop, just not not changing the loop order to match their desired outcome.
Given that loop order can have behavioral impact (and I would never trust an LLM to be able to tell if it did), that seems like the correct behavior to me though
@whitequark @porglezomp -
i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
the "ideal" (their choice of words) case is 64.2%
@whitequark The Code Randomizer (TM)
-
i'm at a loss of words after reading a paper about reformatting code using an ML model that has a measured statistical quantity A_c which says how often the reformatted code behaves the same as the original
the "ideal" (their choice of words) case is 64.2%
@whitequark well two out of three ain’t bad. No, wait…