gemma 4 e4b isn't half shabby, but i didn't think it would run in llama.cpp-vulkan in ubuntu on this lenovo yoga laptop with an AMD Radeon 860M GPU.
-
gemma 4 e4b isn't half shabby, but i didn't think it would run in llama.cpp-vulkan in ubuntu on this lenovo yoga laptop with an AMD Radeon 860M GPU.
Q8_0 (~8GB), 17 tokens/secs. real nice.
i need to read google's paper on this and the novel compression method they used.
maybe these new datacenters can eventually go fuck themselves after all
@lritter
If you'd like some hints:
- Gemma 4 support was broken some time. Use latest llama.cpp and redownload the quants if they are older than this week.
- Don't use vibe tools (just my personal opinion) but IDE integration like kilocode
- In my experience Qwen3.5 still beats Gemma for coding tasks. Probably depends on the programming language.
- The E4B model is strong for everyday tasks (Simple problems, translation from/to good supported languages, grammar checking) -
my impression so far is that a lot of infrastructurd is being built on top the assumption that transformer llm's will eventually be replaced by something that actually works and learns. all of this has tech demo quality. i feel sorry for everyone forced by their boss to argue with the machine like they are in a douglas adams novel.
@lritter I gather the LLM companies are begging for investment on the basis that they're close to building that thing, then spending the money on LLMing harder / buying all the GPUs so their competitors can't LLM as hard / offering services at a loss so they have lots of "users" to impress investors with; they have no idea how to actually produce a more functional AI so just LLM harder and get incremental gains for exponentially rising costs.
-
@lritter
If you'd like some hints:
- Gemma 4 support was broken some time. Use latest llama.cpp and redownload the quants if they are older than this week.
- Don't use vibe tools (just my personal opinion) but IDE integration like kilocode
- In my experience Qwen3.5 still beats Gemma for coding tasks. Probably depends on the programming language.
- The E4B model is strong for everyday tasks (Simple problems, translation from/to good supported languages, grammar checking)- i'm aware. this is all new. new llama, new files. i use the exact temperature, top k etc. config as suggested by the vendor. examples in this thread were all 26b based. 34b is too slow for tools.
- i would rather have my fingernails pulled out than put this in a IDE and compromise integrity & copyright. this is strictly entertainment.
- i doubt the speed is the same. i'm going to try a qwen 3.5 35B A3B, let's see if it can understand my work. i doubt it.
- agree on e4b.
-
my impression so far is that a lot of infrastructurd is being built on top the assumption that transformer llm's will eventually be replaced by something that actually works and learns. all of this has tech demo quality. i feel sorry for everyone forced by their boss to argue with the machine like they are in a douglas adams novel.
@lritter I'm honestly surprised that you even came that far with such a tiny model and probably a tiny context window as well. And yes, everything below the big frontier models still feels very much like a tech demo. Impressive, but not really useful. Even the smaller Claude models (Sonnet, Haiku) are relatively shit when used for anything more complex.
-
@lritter I'm honestly surprised that you even came that far with such a tiny model and probably a tiny context window as well. And yes, everything below the big frontier models still feels very much like a tech demo. Impressive, but not really useful. Even the smaller Claude models (Sonnet, Haiku) are relatively shit when used for anything more complex.
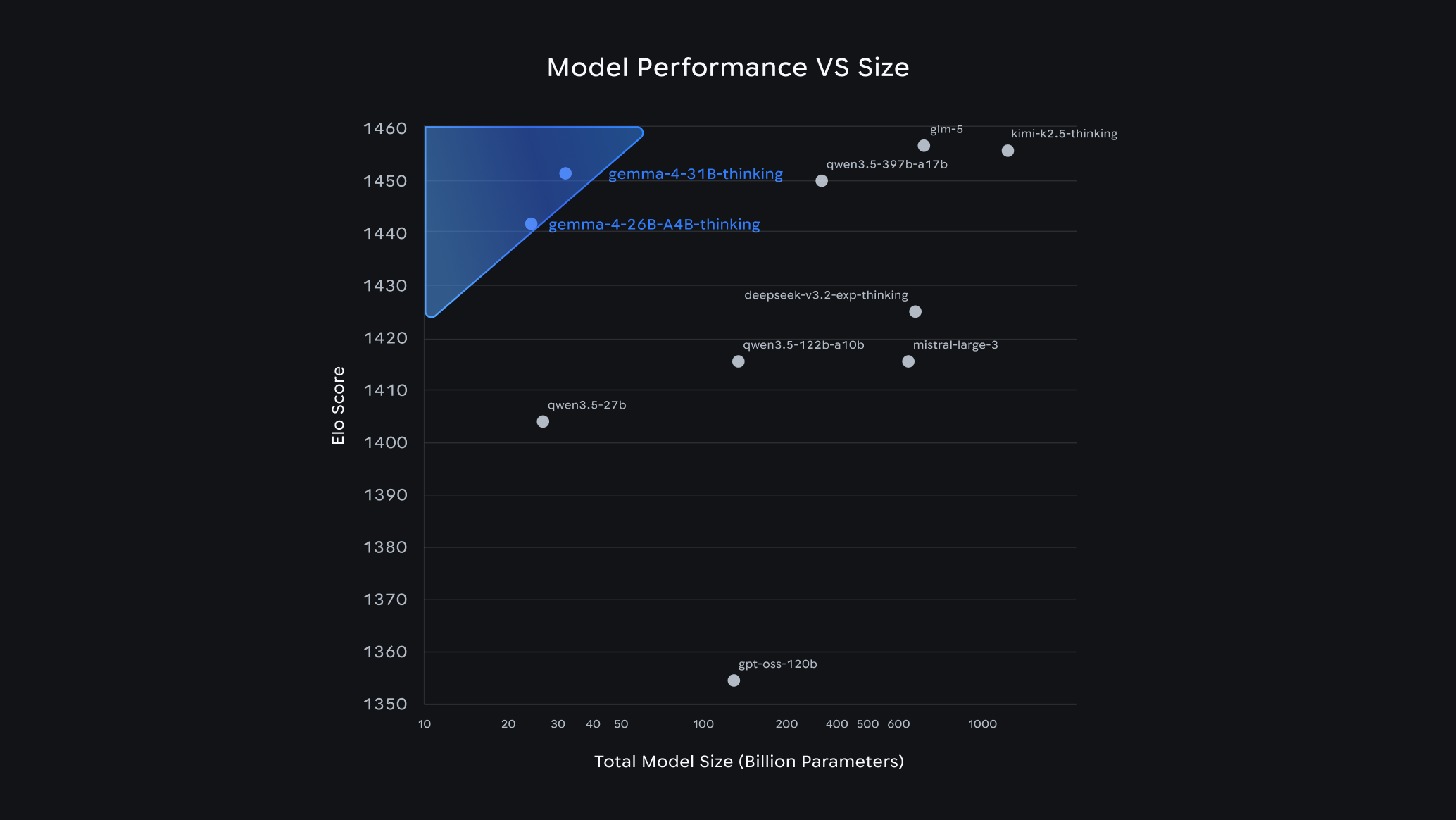
@neo it's the 26b model, not that tiny. 128k context window. google calls the 34b version a "frontier model".
-
@neo it's the 26b model, not that tiny. 128k context window. google calls the 34b version a "frontier model".
@lritter That is tiny.
") The big ones are in the range of > 1 trillion parameters (not all activated at once) and up to 1m context window, and it shows.
The big ones are in the range of > 1 trillion parameters (not all activated at once) and up to 1m context window, and it shows. -
@lritter That is tiny.
The big ones are in the range of > 1 trillion parameters (not all activated at once) and up to 1m context window, and it shows.@neo you should know it's not the size that matters.

-
@neo you should know it's not the size that matters.
@lritter Yeah yeah, just use your VRAM smarter. That's what Nvidia said when they released another 8 GB card.

-
- i'm aware. this is all new. new llama, new files. i use the exact temperature, top k etc. config as suggested by the vendor. examples in this thread were all 26b based. 34b is too slow for tools.
- i would rather have my fingernails pulled out than put this in a IDE and compromise integrity & copyright. this is strictly entertainment.
- i doubt the speed is the same. i'm going to try a qwen 3.5 35B A3B, let's see if it can understand my work. i doubt it.
- agree on e4b.
@allo i set up the qwen model i mentioned with the settings recommended for coding work. it is slower but not impossibly slow. 12t/s
i had it examine the nudl directory, read the sx docs, etc.
tutorial is also full-blown wrong.
(fun fact: when i scolded gemma for the bad quality of it earlier, it wrote it again, and this time, more things were correct.)
but this is a joke. i expect one shot perfection.
-
@allo i set up the qwen model i mentioned with the settings recommended for coding work. it is slower but not impossibly slow. 12t/s
i had it examine the nudl directory, read the sx docs, etc.
tutorial is also full-blown wrong.
(fun fact: when i scolded gemma for the bad quality of it earlier, it wrote it again, and this time, more things were correct.)
but this is a joke. i expect one shot perfection.
@allo i also told qwen it did a bad job and now it wants to know what it did wrong? if i could only explain, it would understand.
goes to show: these models can only help you when you're not doing anything interesting.
-
@allo i also told qwen it did a bad job and now it wants to know what it did wrong? if i could only explain, it would understand.
goes to show: these models can only help you when you're not doing anything interesting.
@allo qwen 3.5
-
@allo qwen 3.5
@lritter I am not sure what frontend you are using there. I think one of the advantages of kilocode (or roo) is that it provides good tools for dissecting the source and thought out system prompts. A one-shot in the web interface doesn't do the same than a command in kilocode.
Yeah, 27B/34B dense are too slow for me, too, but the MoE work for me. I need to reevaluate Gemma 4 after the latest fixes, it may now perform better.
And I guess having AI work with a novel programming language is hard.
-
@lritter I am not sure what frontend you are using there. I think one of the advantages of kilocode (or roo) is that it provides good tools for dissecting the source and thought out system prompts. A one-shot in the web interface doesn't do the same than a command in kilocode.
Yeah, 27B/34B dense are too slow for me, too, but the MoE work for me. I need to reevaluate Gemma 4 after the latest fixes, it may now perform better.
And I guess having AI work with a novel programming language is hard.
@lritter For the rest: I know you are not too fond of LLMs or AI, and I guess we don't need to discuss this in detail. But for me, they do well within the range that one can expect of them, even for one-shotting medium sized scripts.
My take is that these things won't go away, so one should take what's useful and leave the rest. And don't fall for the hyped things like Openclaw.
-
@lritter I am not sure what frontend you are using there. I think one of the advantages of kilocode (or roo) is that it provides good tools for dissecting the source and thought out system prompts. A one-shot in the web interface doesn't do the same than a command in kilocode.
Yeah, 27B/34B dense are too slow for me, too, but the MoE work for me. I need to reevaluate Gemma 4 after the latest fixes, it may now perform better.
And I guess having AI work with a novel programming language is hard.
@allo it's because they are not really good at doing mental transfer work themselves. they are not intelligent in any meaningful way. they just know what fits best. for many tasks, that is exactly what you want. but when it comes to what *feels* best... they're just like high functioning autists doing a hell of a masking job.
-
@allo it's because they are not really good at doing mental transfer work themselves. they are not intelligent in any meaningful way. they just know what fits best. for many tasks, that is exactly what you want. but when it comes to what *feels* best... they're just like high functioning autists doing a hell of a masking job.
@lritter I've once read they are a multiplier. Making the dumb people dumber and the clever people more clever.
Like you can outsource things and blindly believe the output and fail hard, or you know exactly how to use them and speed up your work a lot.
Another interesting aspect: First people reported burnout from using LLMs, because they are much more productive, and that led to doing much more in a day than they would when doing things themselves, while the work is still mentally straining.
-
@lritter I've once read they are a multiplier. Making the dumb people dumber and the clever people more clever.
Like you can outsource things and blindly believe the output and fail hard, or you know exactly how to use them and speed up your work a lot.
Another interesting aspect: First people reported burnout from using LLMs, because they are much more productive, and that led to doing much more in a day than they would when doing things themselves, while the work is still mentally straining.
@allo i know of that aspect.
> Making the dumb people dumber and the clever people more clever.
yes but which of the two am i!
-
@lritter I've once read they are a multiplier. Making the dumb people dumber and the clever people more clever.
Like you can outsource things and blindly believe the output and fail hard, or you know exactly how to use them and speed up your work a lot.
Another interesting aspect: First people reported burnout from using LLMs, because they are much more productive, and that led to doing much more in a day than they would when doing things themselves, while the work is still mentally straining.
@lritter
The AI assisted 10x engineer, I guess. -
@lritter
The AI assisted 10x engineer, I guess.@allo all this sounds more like mythbuilding to me than truth.
-
@allo i know of that aspect.
> Making the dumb people dumber and the clever people more clever.
yes but which of the two am i!
@lritter
Be the zero, its not affected by multipliers!
-
@allo all this sounds more like mythbuilding to me than truth.
@lritter
No idea, butI think it is plausibel that doing more even with a tool is more stressful than doing less by hand. I think it was particularly about coding work.