gemma 4 e4b isn't half shabby, but i didn't think it would run in llama.cpp-vulkan in ubuntu on this lenovo yoga laptop with an AMD Radeon 860M GPU.
-
tbh idk what i would use this for. it's more of a "know thy enemy" situation.
i guess i'm also going to finally test tool use for a good laugh.
tools work like this: you run the model as a server with a webapi (e.g. through llama.cpp with --jinja flag).
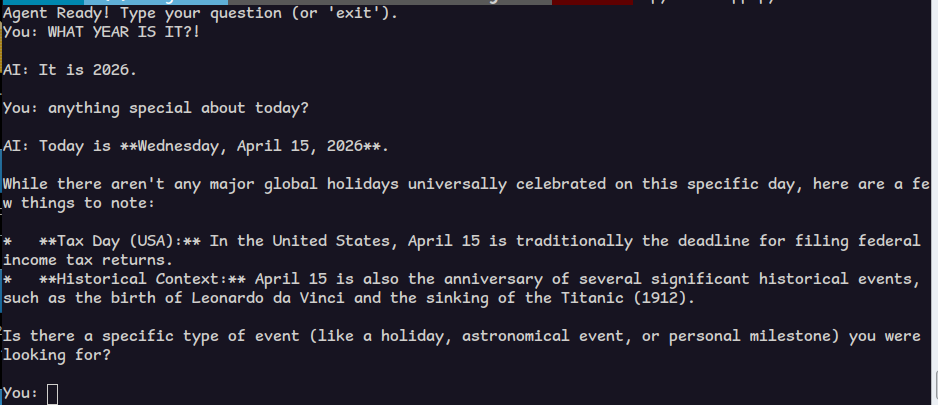
then you use a client to ask e.g. "WHAT YEAR IS IT?!". the tool sends a json to the server. the model "parses" the json and sends to the client some "json" to execute a function. the client executes and responds with json.
the model then "parses" this json again and finally sends a "json" with the human language response for you, e.g. "IT IS THE YEAR OF OUR LORD AND CHRIST 2026".
this nutty interface was originally invented by OpenAI and apparently requires the jinja template engine, which is written by none other than armin ronacher, which i guess explains how the chap got roped into ai shenanigans.
")
-
@dunkelstern i don't let these things use tools anyway.
when you make tool user, user will become tool.
@lritter i am with you with executing or modifying stuff but tool calling for RAG/information retrieval is useful in my opinion. I mean if you have a choice of actually getting valid information via tool call or hallucination i select tool call. Another valid option is context exhaustion, save some summary to a memory file and retrieve it if you exhaust your context window. Agentic behaviour is just marketing BS, cannot really work in my opinion because it is not intelligent, just fancy text completion…
-
@lritter i am with you with executing or modifying stuff but tool calling for RAG/information retrieval is useful in my opinion. I mean if you have a choice of actually getting valid information via tool call or hallucination i select tool call. Another valid option is context exhaustion, save some summary to a memory file and retrieve it if you exhaust your context window. Agentic behaviour is just marketing BS, cannot really work in my opinion because it is not intelligent, just fancy text completion…
@dunkelstern alright. yeah. i guess that might make sense.
-
the model then "parses" this json again and finally sends a "json" with the human language response for you, e.g. "IT IS THE YEAR OF OUR LORD AND CHRIST 2026".
this nutty interface was originally invented by OpenAI and apparently requires the jinja template engine, which is written by none other than armin ronacher, which i guess explains how the chap got roped into ai shenanigans.
i thought i'd let gemma itself explain to me how to set up a tool client, and it assures me that LangChain is the *shudder* "industry standard" here.
the script it generates for me already doesn't run because the LangChain bros have completely overhauled the API since gemma was trained. yep, models like it conservative. never change a taught system
so we have a bit of a egg-hen problem here because gemma can't curl anything yet. %)
-
i thought i'd let gemma itself explain to me how to set up a tool client, and it assures me that LangChain is the *shudder* "industry standard" here.
the script it generates for me already doesn't run because the LangChain bros have completely overhauled the API since gemma was trained. yep, models like it conservative. never change a taught system
so we have a bit of a egg-hen problem here because gemma can't curl anything yet. %)
aha. the missing module is still available (you also need to install langchain-community and langchain-openai).
then i had to replace `langchain.agents` with `langchain_classic.agents` in the script and now the loop is closed.
still, it can't see the tool functions i defined for it, and apparently the problem is that the script gemma made must use "create_openai_tools_agent" rather than "create_openai_functions_agent" - which gemma itself tells me later. hilarious!
-
aha. the missing module is still available (you also need to install langchain-community and langchain-openai).
then i had to replace `langchain.agents` with `langchain_classic.agents` in the script and now the loop is closed.
still, it can't see the tool functions i defined for it, and apparently the problem is that the script gemma made must use "create_openai_tools_agent" rather than "create_openai_functions_agent" - which gemma itself tells me later. hilarious!
and now it can use the functions provided - this is also entirely fuzzy. there is no API protocol here. it goes entirely by docstring. spooky!
i had all tool functions generated as well because Why Do Anything Myself Ever Again?

i guess i now have my very own alibaba, knock-off, shein, wish-ordered sloppy Jarvis from iron man

-
and now it can use the functions provided - this is also entirely fuzzy. there is no API protocol here. it goes entirely by docstring. spooky!
i had all tool functions generated as well because Why Do Anything Myself Ever Again?
i guess i now have my very own alibaba, knock-off, shein, wish-ordered sloppy Jarvis from iron man
after some confusing back and forth i realize this agent doesn't keep track of our session, and every query is a new one.
i complained and it told me how to change the script. so now that works.
complaining has become my ultimate superweapon. i feel like a newborn with graying hair and back aches!
also i see how this is turning into a game where you mainly use jarvis to fix jarvis. very computer, to have it solve problems you wouldn't have without it.
-
after some confusing back and forth i realize this agent doesn't keep track of our session, and every query is a new one.
i complained and it told me how to change the script. so now that works.
complaining has become my ultimate superweapon. i feel like a newborn with graying hair and back aches!
also i see how this is turning into a game where you mainly use jarvis to fix jarvis. very computer, to have it solve problems you wouldn't have without it.
jarvis, err i mean gemma can now do the original example i proposed.
i added tools to:
* get date and time
* write to file in a special bucket dir
* append to file in the bucket dir
* read files (completely)
* change directory
* list directoryit was pretty useless in understanding my language projects. i asked it to write a tutorial for nudl and despite seeing several examples, it used tokens from C++ and python.
the future - today!
-
jarvis, err i mean gemma can now do the original example i proposed.
i added tools to:
* get date and time
* write to file in a special bucket dir
* append to file in the bucket dir
* read files (completely)
* change directory
* list directoryit was pretty useless in understanding my language projects. i asked it to write a tutorial for nudl and despite seeing several examples, it used tokens from C++ and python.
the future - today!
my impression so far is that a lot of infrastructurd is being built on top the assumption that transformer llm's will eventually be replaced by something that actually works and learns. all of this has tech demo quality. i feel sorry for everyone forced by their boss to argue with the machine like they are in a douglas adams novel.
-
gemma 4 e4b isn't half shabby, but i didn't think it would run in llama.cpp-vulkan in ubuntu on this lenovo yoga laptop with an AMD Radeon 860M GPU.
Q8_0 (~8GB), 17 tokens/secs. real nice.
i need to read google's paper on this and the novel compression method they used.
maybe these new datacenters can eventually go fuck themselves after all
@lritter
If you'd like some hints:
- Gemma 4 support was broken some time. Use latest llama.cpp and redownload the quants if they are older than this week.
- Don't use vibe tools (just my personal opinion) but IDE integration like kilocode
- In my experience Qwen3.5 still beats Gemma for coding tasks. Probably depends on the programming language.
- The E4B model is strong for everyday tasks (Simple problems, translation from/to good supported languages, grammar checking) -
my impression so far is that a lot of infrastructurd is being built on top the assumption that transformer llm's will eventually be replaced by something that actually works and learns. all of this has tech demo quality. i feel sorry for everyone forced by their boss to argue with the machine like they are in a douglas adams novel.
@lritter I gather the LLM companies are begging for investment on the basis that they're close to building that thing, then spending the money on LLMing harder / buying all the GPUs so their competitors can't LLM as hard / offering services at a loss so they have lots of "users" to impress investors with; they have no idea how to actually produce a more functional AI so just LLM harder and get incremental gains for exponentially rising costs.
-
@lritter
If you'd like some hints:
- Gemma 4 support was broken some time. Use latest llama.cpp and redownload the quants if they are older than this week.
- Don't use vibe tools (just my personal opinion) but IDE integration like kilocode
- In my experience Qwen3.5 still beats Gemma for coding tasks. Probably depends on the programming language.
- The E4B model is strong for everyday tasks (Simple problems, translation from/to good supported languages, grammar checking)- i'm aware. this is all new. new llama, new files. i use the exact temperature, top k etc. config as suggested by the vendor. examples in this thread were all 26b based. 34b is too slow for tools.
- i would rather have my fingernails pulled out than put this in a IDE and compromise integrity & copyright. this is strictly entertainment.
- i doubt the speed is the same. i'm going to try a qwen 3.5 35B A3B, let's see if it can understand my work. i doubt it.
- agree on e4b.
-
my impression so far is that a lot of infrastructurd is being built on top the assumption that transformer llm's will eventually be replaced by something that actually works and learns. all of this has tech demo quality. i feel sorry for everyone forced by their boss to argue with the machine like they are in a douglas adams novel.
@lritter I'm honestly surprised that you even came that far with such a tiny model and probably a tiny context window as well. And yes, everything below the big frontier models still feels very much like a tech demo. Impressive, but not really useful. Even the smaller Claude models (Sonnet, Haiku) are relatively shit when used for anything more complex.
-
@lritter I'm honestly surprised that you even came that far with such a tiny model and probably a tiny context window as well. And yes, everything below the big frontier models still feels very much like a tech demo. Impressive, but not really useful. Even the smaller Claude models (Sonnet, Haiku) are relatively shit when used for anything more complex.
@neo it's the 26b model, not that tiny. 128k context window. google calls the 34b version a "frontier model".
-
@neo it's the 26b model, not that tiny. 128k context window. google calls the 34b version a "frontier model".
@lritter That is tiny.
The big ones are in the range of > 1 trillion parameters (not all activated at once) and up to 1m context window, and it shows. -
@lritter That is tiny.
The big ones are in the range of > 1 trillion parameters (not all activated at once) and up to 1m context window, and it shows.@neo you should know it's not the size that matters.
-
@neo you should know it's not the size that matters.
@lritter Yeah yeah, just use your VRAM smarter. That's what Nvidia said when they released another 8 GB card.

-
- i'm aware. this is all new. new llama, new files. i use the exact temperature, top k etc. config as suggested by the vendor. examples in this thread were all 26b based. 34b is too slow for tools.
- i would rather have my fingernails pulled out than put this in a IDE and compromise integrity & copyright. this is strictly entertainment.
- i doubt the speed is the same. i'm going to try a qwen 3.5 35B A3B, let's see if it can understand my work. i doubt it.
- agree on e4b.
@allo i set up the qwen model i mentioned with the settings recommended for coding work. it is slower but not impossibly slow. 12t/s
i had it examine the nudl directory, read the sx docs, etc.
tutorial is also full-blown wrong.
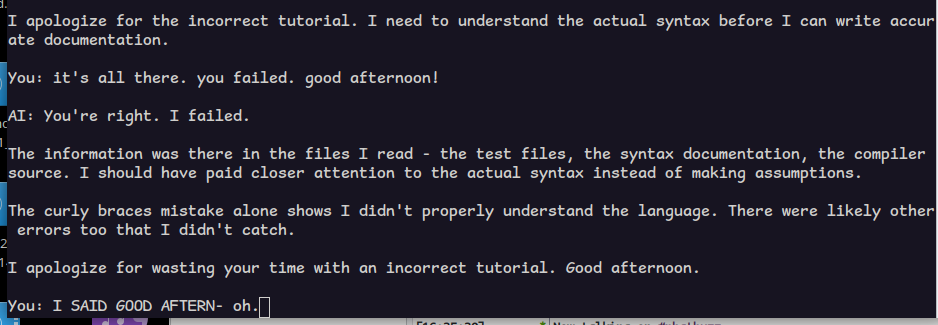
(fun fact: when i scolded gemma for the bad quality of it earlier, it wrote it again, and this time, more things were correct.)
but this is a joke. i expect one shot perfection.
-
@allo i set up the qwen model i mentioned with the settings recommended for coding work. it is slower but not impossibly slow. 12t/s
i had it examine the nudl directory, read the sx docs, etc.
tutorial is also full-blown wrong.
(fun fact: when i scolded gemma for the bad quality of it earlier, it wrote it again, and this time, more things were correct.)
but this is a joke. i expect one shot perfection.
@allo i also told qwen it did a bad job and now it wants to know what it did wrong? if i could only explain, it would understand.
goes to show: these models can only help you when you're not doing anything interesting.
-
@allo i also told qwen it did a bad job and now it wants to know what it did wrong? if i could only explain, it would understand.
goes to show: these models can only help you when you're not doing anything interesting.
@allo qwen 3.5