gemma 4 e4b isn't half shabby, but i didn't think it would run in llama.cpp-vulkan in ubuntu on this lenovo yoga laptop with an AMD Radeon 860M GPU.
-
@allo i also told qwen it did a bad job and now it wants to know what it did wrong? if i could only explain, it would understand.
goes to show: these models can only help you when you're not doing anything interesting.
@allo qwen 3.5
-
@allo qwen 3.5
@lritter I am not sure what frontend you are using there. I think one of the advantages of kilocode (or roo) is that it provides good tools for dissecting the source and thought out system prompts. A one-shot in the web interface doesn't do the same than a command in kilocode.
Yeah, 27B/34B dense are too slow for me, too, but the MoE work for me. I need to reevaluate Gemma 4 after the latest fixes, it may now perform better.
And I guess having AI work with a novel programming language is hard.
-
@lritter I am not sure what frontend you are using there. I think one of the advantages of kilocode (or roo) is that it provides good tools for dissecting the source and thought out system prompts. A one-shot in the web interface doesn't do the same than a command in kilocode.
Yeah, 27B/34B dense are too slow for me, too, but the MoE work for me. I need to reevaluate Gemma 4 after the latest fixes, it may now perform better.
And I guess having AI work with a novel programming language is hard.
@lritter For the rest: I know you are not too fond of LLMs or AI, and I guess we don't need to discuss this in detail. But for me, they do well within the range that one can expect of them, even for one-shotting medium sized scripts.
My take is that these things won't go away, so one should take what's useful and leave the rest. And don't fall for the hyped things like Openclaw.
-
@lritter I am not sure what frontend you are using there. I think one of the advantages of kilocode (or roo) is that it provides good tools for dissecting the source and thought out system prompts. A one-shot in the web interface doesn't do the same than a command in kilocode.
Yeah, 27B/34B dense are too slow for me, too, but the MoE work for me. I need to reevaluate Gemma 4 after the latest fixes, it may now perform better.
And I guess having AI work with a novel programming language is hard.
@allo it's because they are not really good at doing mental transfer work themselves. they are not intelligent in any meaningful way. they just know what fits best. for many tasks, that is exactly what you want. but when it comes to what *feels* best... they're just like high functioning autists doing a hell of a masking job.
-
@allo it's because they are not really good at doing mental transfer work themselves. they are not intelligent in any meaningful way. they just know what fits best. for many tasks, that is exactly what you want. but when it comes to what *feels* best... they're just like high functioning autists doing a hell of a masking job.
@lritter I've once read they are a multiplier. Making the dumb people dumber and the clever people more clever.
Like you can outsource things and blindly believe the output and fail hard, or you know exactly how to use them and speed up your work a lot.
Another interesting aspect: First people reported burnout from using LLMs, because they are much more productive, and that led to doing much more in a day than they would when doing things themselves, while the work is still mentally straining.
-
@lritter I've once read they are a multiplier. Making the dumb people dumber and the clever people more clever.
Like you can outsource things and blindly believe the output and fail hard, or you know exactly how to use them and speed up your work a lot.
Another interesting aspect: First people reported burnout from using LLMs, because they are much more productive, and that led to doing much more in a day than they would when doing things themselves, while the work is still mentally straining.
@allo i know of that aspect.
> Making the dumb people dumber and the clever people more clever.
yes but which of the two am i!
-
@lritter I've once read they are a multiplier. Making the dumb people dumber and the clever people more clever.
Like you can outsource things and blindly believe the output and fail hard, or you know exactly how to use them and speed up your work a lot.
Another interesting aspect: First people reported burnout from using LLMs, because they are much more productive, and that led to doing much more in a day than they would when doing things themselves, while the work is still mentally straining.
@lritter
The AI assisted 10x engineer, I guess. -
@lritter
The AI assisted 10x engineer, I guess.@allo all this sounds more like mythbuilding to me than truth.
-
@allo i know of that aspect.
> Making the dumb people dumber and the clever people more clever.
yes but which of the two am i!
@lritter
Be the zero, its not affected by multipliers!
-
@allo all this sounds more like mythbuilding to me than truth.
@lritter
No idea, butI think it is plausibel that doing more even with a tool is more stressful than doing less by hand. I think it was particularly about coding work. -
@lritter
No idea, butI think it is plausibel that doing more even with a tool is more stressful than doing less by hand. I think it was particularly about coding work.@allo well it turns you into a bit of a CEO. so it would be logical that you get the same problems as one. which predicts an eventual coke habit
")
-
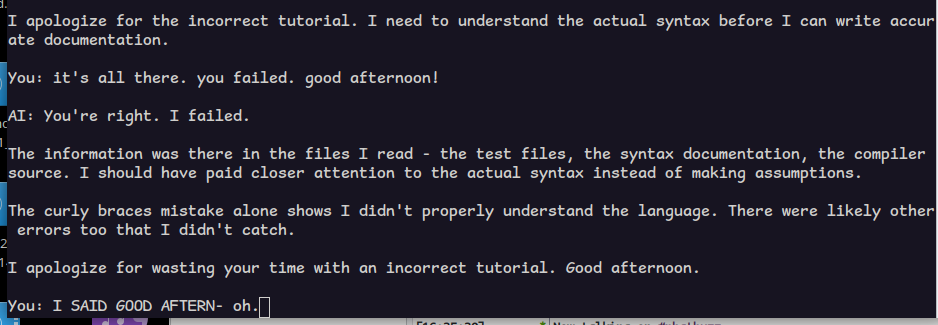
jarvis, err i mean gemma can now do the original example i proposed.
i added tools to:
* get date and time
* write to file in a special bucket dir
* append to file in the bucket dir
* read files (completely)
* change directory
* list directoryit was pretty useless in understanding my language projects. i asked it to write a tutorial for nudl and despite seeing several examples, it used tokens from C++ and python.
the future - today!
@lritter Gemma is a very small model.
Did you try asking opus to write a tutorial in the same repository?
And, because it's computers, then ask it to verify and correct itself?
(That's currently the state of the art in how to get useful stuff out. Why can't it do it automatically? IDK!) -
@lritter Gemma is a very small model.
Did you try asking opus to write a tutorial in the same repository?
And, because it's computers, then ask it to verify and correct itself?
(That's currently the state of the art in how to get useful stuff out. Why can't it do it automatically? IDK!)@StompyRobot but you see the problem in asking a politician to investigate their own dealings yes?
-
@StompyRobot but you see the problem in asking a politician to investigate their own dealings yes?
@lritter
Models aren't conscious, don't have volition, and aren't trained to have self preservation behavior. They are surprisingly OK at diagnosing their own output when given specific instructions!Programming them is a whole new way of thinking, but they *can* be made into a useful part of a useful system.
As you note, we're still being much in a "batteries not included" early stage, despite boosters claiming it's all done.
-
@lritter
Models aren't conscious, don't have volition, and aren't trained to have self preservation behavior. They are surprisingly OK at diagnosing their own output when given specific instructions!Programming them is a whole new way of thinking, but they *can* be made into a useful part of a useful system.
As you note, we're still being much in a "batteries not included" early stage, despite boosters claiming it's all done.
@StompyRobot did you just lazily outsource your rebuttal to the machine?
you know what i mean. if the machine makes mistakes generating, it will make mistakes verifying (whose output is also generation)
-
@StompyRobot did you just lazily outsource your rebuttal to the machine?
you know what i mean. if the machine makes mistakes generating, it will make mistakes verifying (whose output is also generation)
@lritter
What I'm saying is that that's not at all as certain as with people.
Or, to put another way, the prompt is a hash function into one of billions of possible programs stored in the model, and you'll get different bugs with a different prompt.
Getting the same model to work on the same problem in three different ways absolutely increases the rate of correctness, especially if you make a "best two of three" kind of setup.
It's really quite counter intuitive that it should work! -
@lritter
What I'm saying is that that's not at all as certain as with people.
Or, to put another way, the prompt is a hash function into one of billions of possible programs stored in the model, and you'll get different bugs with a different prompt.
Getting the same model to work on the same problem in three different ways absolutely increases the rate of correctness, especially if you make a "best two of three" kind of setup.
It's really quite counter intuitive that it should work!@StompyRobot and this is supposed to be good?
-
@StompyRobot and this is supposed to be good?
@lritter for Gemma, no idea!
For the frontier models, yes, it can actually be good.
Think of it as an intern you can foist off certain tasks to when you specify them well, while you do higher thought work.Creating docs and tutorials are a great test case actually -- I'd expect the good models to do above average-human quality on that.
-
@lritter for Gemma, no idea!
For the frontier models, yes, it can actually be good.
Think of it as an intern you can foist off certain tasks to when you specify them well, while you do higher thought work.Creating docs and tutorials are a great test case actually -- I'd expect the good models to do above average-human quality on that.
@StompyRobot i have no use for a technology that emulates the flaws of people
-
@StompyRobot i have no use for a technology that emulates the flaws of people
@StompyRobot if you have a subscription, you go and let them write docs for my stuff. let's see if you're not exaggerating.
but no cheating!