Pleased to share a page and explainer for the AI tarpit project Science is Poetry, with legal statement, rationale(s), and a few deployment notes:
-
@JulianOliver peer-reviewed just isn’t what it used to be

-
@JulianOliver peer-reviewed just isn’t what it used to be
@scott haha
-
@JulianOliver @asrg@tldr.nettime.org What happened to this account/website?
@caleb oh dear, I don't know. Perhaps down while working on it?
-
@JulianOliver
That’s beautiful
-
Do you have an unused domain that you would be happy to donate to a counter-offensive against unchecked & unregulated AI crawlers that scrape human-made content to simulate & deceive for profit?
If so, pls reply to this post. Your domain would become an entrypoint to the AI tarpit & Poison-as-a-Service project below, allowing concerned public to choose to use it on their sites, helping make the project more resilient to blacklisting.
@JulianOliver several, hit me up
-
It's approaching DoS at this point. This just one of the VMs, and just OpenAI's parasite.
Threading's holding up but need some more tuning of rate limits and burst. Trying sending 429's now to ask them to play nice.
To think the www was built for people.
And here we are
@JulianOliver could you explain what we are seeing here , for dummies ;-))) Is this different to cookies , and “normal” background web activity as a result of search.
-
@JulianOliver could you explain what we are seeing here , for dummies ;-))) Is this different to cookies , and “normal” background web activity as a result of search.
@paulhanrahan Sure! This is log output captured on the server itself, not a local machine. Each line is a page read (an 'HTTP GET' request) by an AI crawler. At the time this was captured, the crawlers were predominantly those of OpenAI, Meta and Anthropic. If you look closely at the log output, you will be able to pick out the 'user agent' strings (declared client identities) of those bots.
-
@JulianOliver found another great one. Maybe the greatest of all time:
https://madhattercorp.com/blog/hasnt/digitizer%20provided%20obsoleteness

-
@JulianOliver found another great one. Maybe the greatest of all time:
https://madhattercorp.com/blog/hasnt/digitizer%20provided%20obsoleteness
@themadhatter yes that's beautiful alright!
-
My log analysis shows that what these AI crawlers do is swarm content to get around rate limiting; with many end-points each can be limited to sane human defaults and their automation can still harvest content at massive scales from the same source in little time.
I noticed however that (for unknown reasons) Anthropic started reducing the number of crawler endpoints, tapering down traffic from them. So I doubled the rate to 2/s. This added over 100k hits to the logs in a day.
-
If you're interested in learning more about implementations of resistance in this era of unchecked Big AI, direct action strategies and the techno-politics therein, be sure to check out ASRG's site (https://algorithmic-sabotage.gitlab.io/asrg/) and give them a follow here on Mastodon (@asrg).
They've put a lot of heartbeats and neurons - human stuff - into this area.
@JulianOliver both links here are 404s as of today - but i will make a note of this name
")
-
@JulianOliver both links here are 404s as of today - but i will make a note of this name
@xurizaemon Yes, it seems soon after my post they took down the account and page. I don't think the two are related and hope they return soon!
-
My log analysis shows that what these AI crawlers do is swarm content to get around rate limiting; with many end-points each can be limited to sane human defaults and their automation can still harvest content at massive scales from the same source in little time.
I noticed however that (for unknown reasons) Anthropic started reducing the number of crawler endpoints, tapering down traffic from them. So I doubled the rate to 2/s. This added over 100k hits to the logs in a day.
@JulianOliver one strategy to defend against this. A tiny bit memory intensive but I think manageable.
This is not for your project but for anyone defending against I scrapers.
Crawler A pulls page A and gets a link to page B. This is specific to the request and invisible in the page or else try to only serve up to crawlers.
Crawler B tries to pull page B but we know it never pulled page A so can't know about it. Ban both A and B.
This has to check source IP and keep track of that. But!
-
@JulianOliver several, hit me up
@coldclimate Apologies for the delay. If you're still up for it, here are the 2 records needed:
A: 95.216.76.85
AAAA: 2a01:4f9:2b:c83::2Let me know once done and I'll set it all up serverside
-
@JulianOliver i could dedicate subdomains such as science.akselmo.dev to this. Just let me know how.
@aks Apologies for the delay. If you're still up for it, here are the 2 records needed:
A: 95.216.76.85
AAAA: 2a01:4f9:2b:c83::2Let me know once done and I'll set it all up serverside
-
You can add `dreckiger.schleimpilz.ch` to the list. Thanks for all your work!
@thgie I still can't get past how perfect this domain is. Thanks again.
-
@perhammer Apologies for the delay. If you're still up for it, here are the 2 records needed:
A: 95.216.76.85
AAAA: 2a01:4f9:2b:c83::2Let me know once done and I'll set it all up serverside
-
My log analysis shows that what these AI crawlers do is swarm content to get around rate limiting; with many end-points each can be limited to sane human defaults and their automation can still harvest content at massive scales from the same source in little time.
I noticed however that (for unknown reasons) Anthropic started reducing the number of crawler endpoints, tapering down traffic from them. So I doubled the rate to 2/s. This added over 100k hits to the logs in a day.
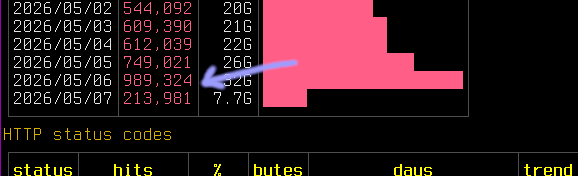
Nearly a month later you would've thought that the crawlers would've given up by now, dropped off, blacklisted the IPs, or perhaps even the domains themselves.
And yet no. As I tentatively guessed, thanks to your donated domains (and the people linking them in their sites) it has only grown.
I don't expect it to run this hot for the long term, but yesterday's hit count (these are almost 100% reads of randomly generated pages by AI crawlers) was near 1M.
-
@thgie I still can't get past how perfect this domain is. Thanks again.
I honestly bought the domain on a whim, because I'm kind of fascinated by slime molds. I'm super happy it finds such useful application. Thanks for all your work, @JulianOliver!
