Bluesky is down today.
-
@mcc@mastodon.social From what I understand of the protocol, they could just stop using a relay at all, but then it would increase the traffic on all the PDS that were scrapped by the relay until then, since the AppView would have to connect to each of those instead of the relay.
And did switching to another relay solved the issue?
@breizh As of this second, Blacksky has resolved the issue. I don't know how.
-
@mcc@mastodon.social @jeromechoo@masto.ai Each post is a dangling request which will consume 3s of CPU time and so 10× consumption of 300ms for alive server, and planned for reschedule. After a while, all workers are just stuck with full of 3s waiting process, with starvation for alive requests.
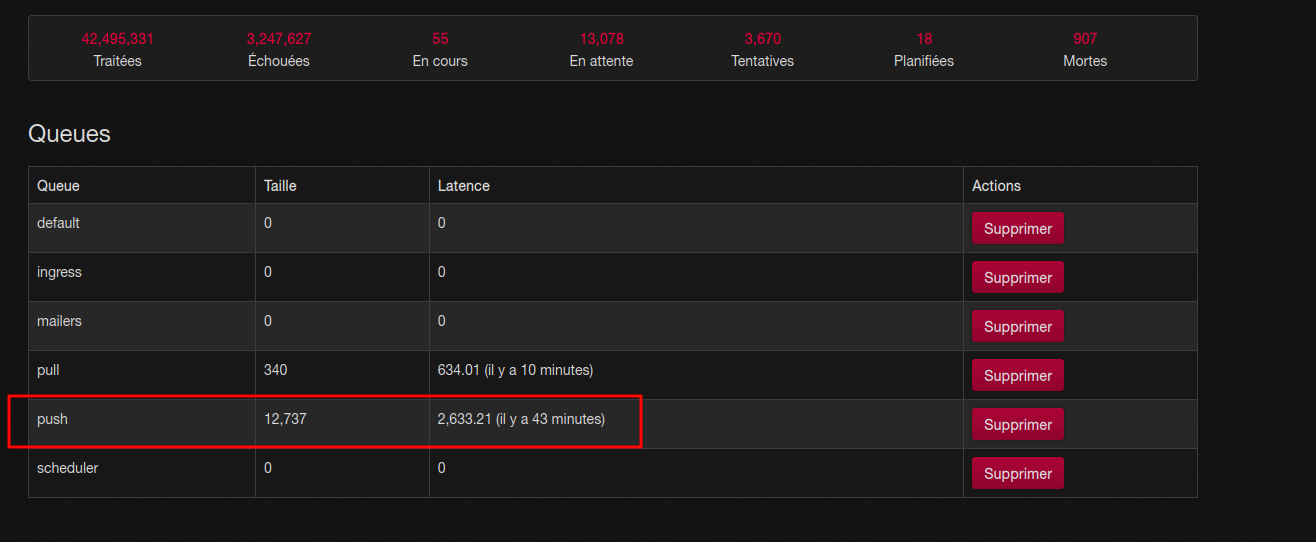
@mcc@mastodon.social @jeromechoo@masto.ai After a while, you have 43 minutes latency for EVERY DELIVERY, even alive server. I experience that on my own Mastodon instance…
-
@mcc@mastodon.social No, it's the trouble with the push design of ActivityPub.
@mcc@mastodon.social @aeris@firefish.imirhil.fr if that's really the case, if anything, that's an implementation problem. Mail servers have dealt with this problem for ages. That's why they have queues and per server exponentially increasing retry intervals. Push is not inherently bad.
-
@mcc this is a really good breakdown, thank you for this thread
-
@jeromechoo@masto.ai @mcc@mastodon.social It affect deliver to masto.ai because EACH of my post generate a dangling request, hiting timeout. After a while, my worker consume more time to dangling request taking 2-3s (hiting timeout) than trying to send content to masto.ai.
-
@mcc@mastodon.social @jeromechoo@masto.ai After a while, you have 43 minutes latency for EVERY DELIVERY, even alive server. I experience that on my own Mastodon instance…
@mcc@mastodon.social @jeromechoo@masto.ai At the end any workers just have 7% of "luck" (3 out of 42) to hit a down request, consuming resource for nothing for 2-3s, having no more time to schedule alive server, with 13.000 pending request because starvation, with many many alive request in those 13.000. Perhaps the 13.000th will be a alive one, but it will be delivered in only 43 minutes in average.
-
@jeromechoo@masto.ai @mcc@mastodon.social No, it not running fine. I ALREADY reported 43 minutes latency to deliver ANY MESSAGE on Mastodon. This "bug" (in fact bad design) is known since ages.
https://github.com/mastodon/mastodon/issues/12445 -
@jeromechoo@masto.ai @mcc@mastodon.social No, it not running fine. I ALREADY reported 43 minutes latency to deliver ANY MESSAGE on Mastodon. This "bug" (in fact bad design) is known since ages.
https://github.com/mastodon/mastodon/issues/12445@mcc@mastodon.social @jeromechoo@masto.ai And my new instance (migrating from Mastodon to Misskey exactly for this reason) is ALREADY filled with 600 dangling requests. At this point it doesn't generate any noticable delay, but only because the overall death rate is low. If a huge instance goes down, it would not be the same at all.
-
@mcc@mastodon.social @jeromechoo@masto.ai At the end any workers just have 7% of "luck" (3 out of 42) to hit a down request, consuming resource for nothing for 2-3s, having no more time to schedule alive server, with 13.000 pending request because starvation, with many many alive request in those 13.000. Perhaps the 13.000th will be a alive one, but it will be delivered in only 43 minutes in average.
-
P2P is a world where naturally the more people use it, the faster and more resilient the network becomes. Load gets distributed. Working nodes talk to each other and ignore nonworking nodes. That's how the primitive, BitTorrent era systems worked.
Bluesky somehow applied superfancy alien future technology to invent P2P traffic jams. When one node goes down, the others go down because they depended on it. Because it's a mesh of interoperating microservices by different providers, not federation.
@mcc the worst are distributed p2p attacks like i watch in ipfs.