Bluesky is down today.
-
@mcc oh! Interesting, I'd just assumed they were already using it.
@thisismissem @mcc probably worth noting that atproto.africa also appears to be down right now, and some microcosm services also appear to be going up and down
firehose.network and the microcosm relays look to be unaffected for now
-
@eestileib @mcc I'm no expert but it honestly sounds like a terrible way to build a network. or at least a pretty confounding way to build a network that you intend to be federated and decentralized in any capacity...
I have a skywalking friend and he says that if blacksky users had configured something in their app to make blacksky primary (which, to be fair, had never mattered before), their timelines would have remained synced with other blacksky users.
And also that blacksky was getting pulled down by bluesky repeatedly coming up, demanding to know the status of every lily in the field, then crashing.
Sounds like they need to come up with a more graceful recovery process and get bluesky to agree with it.
-
@javascript Before I attempt to reply to this, please clarify whether read the post I posted above.
Rudolph Fraser. (@rude1.blacksky.team)
Even their relay seems down(?) Trying to switch some things to use atproto.africa https://atproto.africa

Bluesky Social (bsky.app)
Rudolph Fraser. (@rude1.blacksky.team)
Even their relay seems down(?) Trying to switch some things to use atproto.africa https://atproto.africa

Blacksky (blacksky.community)
Yes, they've been running atproto.africa since last year. But are they *using* it?
I couldn't read the post linked above until you posted it again now, but I thought it was a bug in my software (wafrn) not getting the links right
-
@mcc@mastodon.social Currently i have around 600 "delayed" job because of down instance polluting all delivery. This was reported to Mastodon years ago. Nothing change.
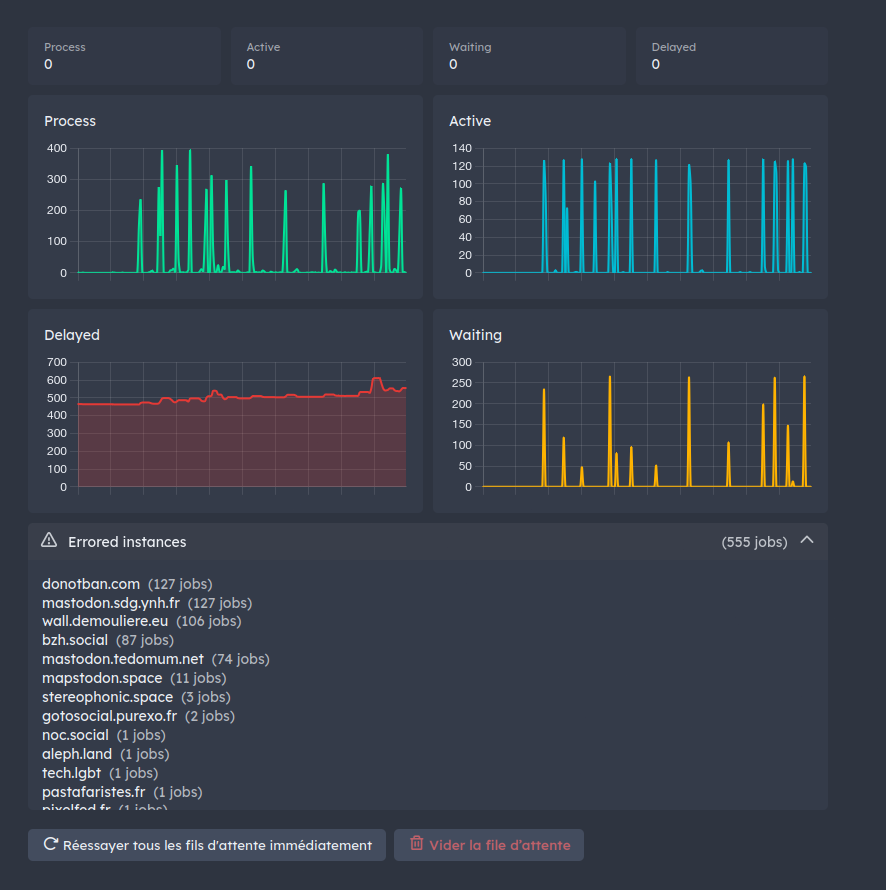
@mcc@mastodon.social For tiny instance, it's not really a trouble, because few message and so queue don't fill.
For huge instance, pretty all message from all instances will generate a dangling request in queue. When queue filled, delay all message for any other instance even the one alive. -
@thisismissem @mcc probably worth noting that atproto.africa also appears to be down right now, and some microcosm services also appear to be going up and down
firehose.network and the microcosm relays look to be unaffected for now
-
I have a skywalking friend and he says that if blacksky users had configured something in their app to make blacksky primary (which, to be fair, had never mattered before), their timelines would have remained synced with other blacksky users.
And also that blacksky was getting pulled down by bluesky repeatedly coming up, demanding to know the status of every lily in the field, then crashing.
Sounds like they need to come up with a more graceful recovery process and get bluesky to agree with it.
@eestileib @nasser Posts hosted on the Blacksky PDS are appearing on the Blacksky AppView immediately. That's definitely true.
-
@mcc@mastodon.social For tiny instance, it's not really a trouble, because few message and so queue don't fill.
For huge instance, pretty all message from all instances will generate a dangling request in queue. When queue filled, delay all message for any other instance even the one alive.@mcc@mastodon.social And it's worst for huge still alive instance. Hundred of message per second. Hundred of job per second for down instance. Hundred of dead job filling queue because timeout, competing resources for alive job. At a point, all workers process only dead job…
-
TLDR
1. My definition of "P2P" or "Federated" is that if server A goes down, servers B and C can still talk to each other.
2. Bluesky/"Atmosphere" fails at this because Blacksky (B) requires Bluesky (A) to talk to me (C).
3. In order for Blacksky to avert this, they have to do something unreasonable and expensive.
4. Blacksky someday *will* do this, but will depend heavily on massively overworking Rudy and a few other people. This may someday fail.
5. ActivityPub has problems, but not these
@mcc This is a good take, mcc.
-
@mcc@mastodon.social And it's worst for huge still alive instance. Hundred of message per second. Hundred of job per second for down instance. Hundred of dead job filling queue because timeout, competing resources for alive job. At a point, all workers process only dead job…
@mcc@mastodon.social I don't know exactly what would be the effect of a 10 hour downtime like bluesky for a mastodon.social downtime for example. I expect at least delay growing over time even from no mastodon.social communication.
-
@mcc@mastodon.social And it's worst for huge still alive instance. Hundred of message per second. Hundred of job per second for down instance. Hundred of dead job filling queue because timeout, competing resources for alive job. At a point, all workers process only dead job…
@aeris If this problem is real I can imagine multiple ways to mitigate it. This is a software engineering problem.
-
@aeris If this problem is real I can imagine multiple ways to mitigate it. This is a software engineering problem.
@mcc@mastodon.social No, it's a design trouble. ActivityPub use push when ATProto use pull.
-
@thisismissem @mcc probably worth noting that atproto.africa also appears to be down right now, and some microcosm services also appear to be going up and down
firehose.network and the microcosm relays look to be unaffected for now
@thisismissem @mcc rose also said a few hours ago that they were fighting a DoS attack; i'd assume whoever is doing the attack is targeting multiple notable services in the ecosystem
-
@mcc@mastodon.social they're allowed to succeed so they can be paraded around thet "see, it's all super distributed and decentralized".
The moment VCs realize they need RoI a bunch of " improvements" likely mostly "for security", probably " for safety", definitely "for the children" will add to the already insane architectural costs, a bunch of operafional burden that makes it impposible for other "instances" to exist.that's the Signal playbook. "sure we can federate, but we won't, for reasons"
CC: @mcc@mastodon.social
-
R relay@relay.infosec.exchange shared this topic
-
@mcc@mastodon.social No, it's a design trouble. ActivityPub use push when ATProto use pull.
@mcc@mastodon.social So by design a down instance pollute everything. You can mitigate that with software yes, but background task scheduling is a hard field.
Pull troubles is simpler to mitigate, because only require throttling output request on down instance after restart after a downtime to avoid hammering other instance to fill the gap. -
@thisismissem @mcc rose also said a few hours ago that they were fighting a DoS attack; i'd assume whoever is doing the attack is targeting multiple notable services in the ecosystem
@esm @mcc yeah, that'd be my guess. It'll be interesting to see if anyone takes responsibility for the attack, if it is an attack as suspected
Tangentially, Russia tried to block bluesky the other day: https://netcrook.com/russia-blocks-bluesky-social-media-crackdown/
-
@mcc@mastodon.social So by design a down instance pollute everything. You can mitigate that with software yes, but background task scheduling is a hard field.
Pull troubles is simpler to mitigate, because only require throttling output request on down instance after restart after a downtime to avoid hammering other instance to fill the gap.@mcc@mastodon.social A down ATP instance is really down. No more pull or effect in the network.
A down AP instance is not really down, all other instances try to communicate with it. -
@thisismissem @mcc rose also said a few hours ago that they were fighting a DoS attack; i'd assume whoever is doing the attack is targeting multiple notable services in the ecosystem
@esm @thisismissem That's interesting, but
1. If it's true, why would the DDOS differentially impact third-party PDSes on Blacksky while Blacksky PDS runs at normal speed?
2. Did atproto go down because of a DOS or because of some side-effect of an attempt to move over to it as the primary relay?
One possibility is the failures I saw were *because* we switched from bluesky to atproto.africa, causing a short netlag period while atproto.africa caught up to the present? I don't know?
-
@esm @thisismissem That's interesting, but
1. If it's true, why would the DDOS differentially impact third-party PDSes on Blacksky while Blacksky PDS runs at normal speed?
2. Did atproto go down because of a DOS or because of some side-effect of an attempt to move over to it as the primary relay?
One possibility is the failures I saw were *because* we switched from bluesky to atproto.africa, causing a short netlag period while atproto.africa caught up to the present? I don't know?
@esm @thisismissem I mean it's certainly possible that I am simply misinterpreting Rudy's comments about relays!… but all we ever get from Rudy are these vague gnomic comments, so this is about the best I can do. I'd rather him be spending his time sysadminining and writing Rust than writing up incident reports for public consumption but it does mean trying to figure out wtf is happening to my feed as a blacksky user is constant detective work
-
@esm @thisismissem That's interesting, but
1. If it's true, why would the DDOS differentially impact third-party PDSes on Blacksky while Blacksky PDS runs at normal speed?
2. Did atproto go down because of a DOS or because of some side-effect of an attempt to move over to it as the primary relay?
One possibility is the failures I saw were *because* we switched from bluesky to atproto.africa, causing a short netlag period while atproto.africa caught up to the present? I don't know?
-
@mcc@mastodon.social A down ATP instance is really down. No more pull or effect in the network.
A down AP instance is not really down, all other instances try to communicate with it.@mcc@mastodon.social And it's a vector attack in theory. You can bootstrap thousands of instance, just subscribing to as many account as possible, and then just shutdown your instance.
Any content from subscribed account will generate a background job to your down instance, then hiting timeout each time.
You can just flood instance like that to continue to overflow queue with dangling content.

