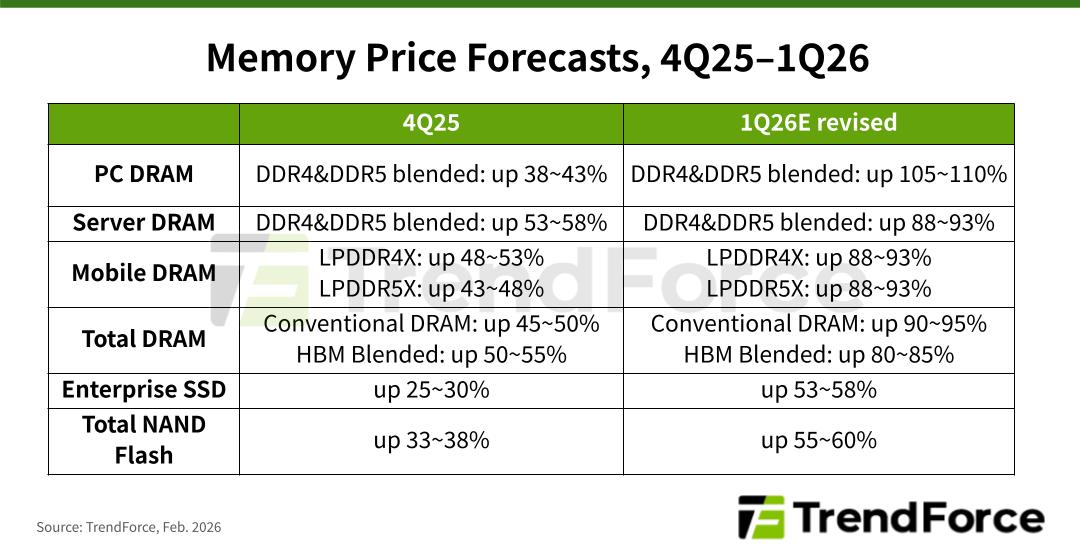
Taalas just emerged from stealth with a claim that’s shaking the hardware world: 17,000 tokens per second on Llama 3.1 8B.
How? By physically etching the AI model directly into the silicon transistors. No HBM. No liquid cooling. Just raw, hardwired performance that is 10x faster and 20x cheaper than traditional GPU inference.
17,000 Tokens/Second: Is Taalas’ Hardwired Silicon the Ultimate Solution to the AI Memory Wall and HBM Shortage?
Can Taalas’ 17,000 tokens/sec HC1 chip solve the AI Memory Wall? Discover why hardwired silicon is disrupting the HBM market and how it impacts GPU resale value.
BuySellRam (www.buysellram.com)
#AI #ArtificialIntelligence #AIHardware #DataCenter #MemoryWall #HBMShortage #InferenceFactory #HardcoreAI #ASIC #Taalas #NVIDIA #technology