Here's a fun low-level concurrency puzzle that I first learned as an interview question:
-
Here's a fun low-level concurrency puzzle that I first learned as an interview question:
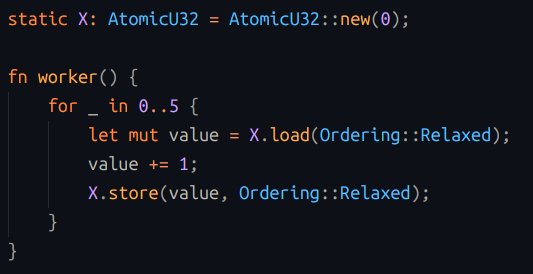
We create a small program, which defines a global integer variable, initialized to zero. The program then spawns five threads. Each thread runs a loop 5 times: on each iteration of the loop it reads the global integer, increments the value by 1, and writes the new value back to the global variable.
When all five threads have completed, the program prints out the value of the global integer. What possible values might this program print?
-
Here's a fun low-level concurrency puzzle that I first learned as an interview question:
We create a small program, which defines a global integer variable, initialized to zero. The program then spawns five threads. Each thread runs a loop 5 times: on each iteration of the loop it reads the global integer, increments the value by 1, and writes the new value back to the global variable.
When all five threads have completed, the program prints out the value of the global integer. What possible values might this program print?
Some clarifications:
1. Assume that we've coded the loop in a way that's non-atomic, but also not undefined behavior, e.g. in assembly using load/increment/store instructions, or in C/C++/Rust using explicit load/store with relaxed ordering. Assume the compiler doesn't optimize the loop away.
2. Yes, this program has race conditions, and its behavior is nondeterministic. We're not trying to "fix" the program, just describe its behavior.
3. You can assume any number of cpus you like, even one. If you have >1 cpus, assume that they share coherent cpu caches, so that each memory store is immediately visible to all other cpus. Or just pretend there's no cpu cache at all.
4. Assume a "normal" operating system that can preempt threads, i.e. something like Linux, not a cooperatively-scheduled RTOS.
-
Some clarifications:
1. Assume that we've coded the loop in a way that's non-atomic, but also not undefined behavior, e.g. in assembly using load/increment/store instructions, or in C/C++/Rust using explicit load/store with relaxed ordering. Assume the compiler doesn't optimize the loop away.
2. Yes, this program has race conditions, and its behavior is nondeterministic. We're not trying to "fix" the program, just describe its behavior.
3. You can assume any number of cpus you like, even one. If you have >1 cpus, assume that they share coherent cpu caches, so that each memory store is immediately visible to all other cpus. Or just pretend there's no cpu cache at all.
4. Assume a "normal" operating system that can preempt threads, i.e. something like Linux, not a cooperatively-scheduled RTOS.
The rest of this thread will include some discussion containing hints, partial solutions, and then the final answer. Just a warning, if you want to try to solve it yourself...
Here's the start of the answer (this isn't the cool part yet): if all threads run sequentially (each thread runs to completion before the next one starts), then the result will be 25 (5 threads each incremented the value 5 times). If all the threads run concurrently, in perfect lockstep (every thread reads 0, writes 1; reads 1, writes 2...), the result will be 5. And you could construct a timeline where some threads run in lockstep for part of the time, and then run sequentially for the rest, so you could get a result anywhere between 5 and 25.
-
The rest of this thread will include some discussion containing hints, partial solutions, and then the final answer. Just a warning, if you want to try to solve it yourself...
Here's the start of the answer (this isn't the cool part yet): if all threads run sequentially (each thread runs to completion before the next one starts), then the result will be 25 (5 threads each incremented the value 5 times). If all the threads run concurrently, in perfect lockstep (every thread reads 0, writes 1; reads 1, writes 2...), the result will be 5. And you could construct a timeline where some threads run in lockstep for part of the time, and then run sequentially for the rest, so you could get a result anywhere between 5 and 25.
Now we come to the surprising bit: 5 is not the lowest value this program could print. In fact, the lowest possible value is 2. How is this possible? What is the sequence of operations that gives this result?
(this is the cool part)
-
Now we come to the surprising bit: 5 is not the lowest value this program could print. In fact, the lowest possible value is 2. How is this possible? What is the sequence of operations that gives this result?
(this is the cool part)
A hint: You get to play the evil kernel scheduler: try to find the worst possible time to suspend and resume threads. You may run threads for as short a time as you like, or suspend them as long as you want, and interleave them in any order you like. How much this resembles actual scheduler behavior probably depends on how cynical you are.
This is a useful technique when analyzing any sort of race condition or lock-free algorithm. Given enough machine-hours, all possible timelines will eventually happen, so we should seek out the corner cases if we're trying to understand the worst-case result.
-
A hint: You get to play the evil kernel scheduler: try to find the worst possible time to suspend and resume threads. You may run threads for as short a time as you like, or suspend them as long as you want, and interleave them in any order you like. How much this resembles actual scheduler behavior probably depends on how cynical you are.
This is a useful technique when analyzing any sort of race condition or lock-free algorithm. Given enough machine-hours, all possible timelines will eventually happen, so we should seek out the corner cases if we're trying to understand the worst-case result.
Working toward the answer, part 1:
Recognize that the global value does not necessary only increase. If threads are suspended by the operating system in the middle of the loop, then we could have thread A stopped after (read 0) then thread B runs (read 0, write 1, read 1, write 2), then thread A awakes and does (write 1). If we watch the global variable over time we can see its value change like this: (0, 1, 2, 1).
-
Working toward the answer, part 1:
Recognize that the global value does not necessary only increase. If threads are suspended by the operating system in the middle of the loop, then we could have thread A stopped after (read 0) then thread B runs (read 0, write 1, read 1, write 2), then thread A awakes and does (write 1). If we watch the global variable over time we can see its value change like this: (0, 1, 2, 1).
Working toward the answer, part 2:
Realize that the number of threads doesn't matter very much in this problem. We can throw out all of the progress made by a thread by having it run all its iterations in between another thread's read and write. So for example if thread A runs (read 0) and then thread B runs (read 0, write 1, ... read 4, write 5) then thread A resumes with (write 1) we just erased all of thread B's work. We can erase the progress of multiple threads this way, so we can just go ahead and pretend there are only two threads that matter.
You could get the same effect by forcing multiple threads to run in lockstep: if threads A,B,C all run simultaneously they will have the same visible effects as a single thread.
-
Working toward the answer, part 2:
Realize that the number of threads doesn't matter very much in this problem. We can throw out all of the progress made by a thread by having it run all its iterations in between another thread's read and write. So for example if thread A runs (read 0) and then thread B runs (read 0, write 1, ... read 4, write 5) then thread A resumes with (write 1) we just erased all of thread B's work. We can erase the progress of multiple threads this way, so we can just go ahead and pretend there are only two threads that matter.
You could get the same effect by forcing multiple threads to run in lockstep: if threads A,B,C all run simultaneously they will have the same visible effects as a single thread.
Working toward the answer, part 3:
We want the final value to be 2, so that tells us that some thread, in its final iteration, wrote a 2. Logically, this means that thread, in its final iteration, read a 1. That seems pretty unlikely, but let's keep going.
We may also observe that no thread will ever write a 0 (because all writes are preceded by a register increment), so the only time (read 0) is possible is in some thread's first iteration. That means the only time (write 1) is possible is in some thread's first iteration.
-
Working toward the answer, part 3:
We want the final value to be 2, so that tells us that some thread, in its final iteration, wrote a 2. Logically, this means that thread, in its final iteration, read a 1. That seems pretty unlikely, but let's keep going.
We may also observe that no thread will ever write a 0 (because all writes are preceded by a register increment), so the only time (read 0) is possible is in some thread's first iteration. That means the only time (write 1) is possible is in some thread's first iteration.
The final answer:
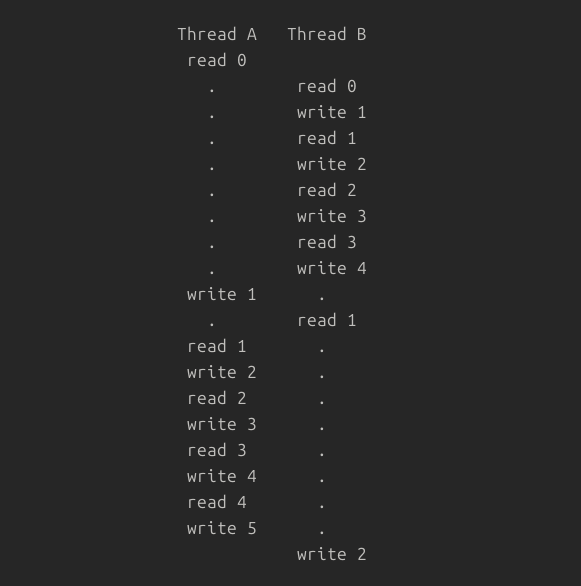
How can we (as the evil kernel scheduler) get this program to print 2?Putting together all we've learned, some thread read a 1 in its final iteration, that must have been written by another thread in its first iteration. So we need a timeline that does this:
Thread A: read 0
Thread B: read 0, write 1, ... read 3, write 4 (4 iterations)
Thread A: write 1
Thread B: read 1 (in its final iteration)
Thread A: read 1, ... write 5 (thread complete)
Thread B: write 2 (thread complete)(Neutralize the other threads by running them all right before some thread is about to write a value.)
-
The final answer:
How can we (as the evil kernel scheduler) get this program to print 2?Putting together all we've learned, some thread read a 1 in its final iteration, that must have been written by another thread in its first iteration. So we need a timeline that does this:
Thread A: read 0
Thread B: read 0, write 1, ... read 3, write 4 (4 iterations)
Thread A: write 1
Thread B: read 1 (in its final iteration)
Thread A: read 1, ... write 5 (thread complete)
Thread B: write 2 (thread complete)(Neutralize the other threads by running them all right before some thread is about to write a value.)
A few questions that might be lingering:
Q: Why is 2 the minimum? Why not 1 or 0?
If the program completed, we know that each thread wrote something. And we also know that all of those writes were >= 1. So we know that 0 isn't possible.
We also know that iterations after the first iteration must have read a value written by some previous iteration (though not necessarily from the same thread). So all later iterations must all read a 1 or higher, so could only write 2 or higher.
Q: What happens in C or C++ if the program doesn't use explicit atomic loads/stores?
As far as I'm aware, in C11/C++11 this is undefined behavior so your program could do anything at all. Earlier standards did not discuss memory races, so racey access to memory is tolerated. However, if you write a loop incrementing an integer five times, the optimizer will probably just optimize the individual increments away and each thread would do "x += 5" instead. But if you disable that optimization you can build the program described here using something like:
int x = 0;
void func() {
for (i=0; i<5; i++) { x++ }
}
(and then add the thread-spawning bits)Q: I tried it and it always prints 25! What's wrong?
The scheduler is being nice to you today. If you want to increase your chances of seeing odd results, run more iterations, and maybe more threads. Or you can add `thread::yield_now()` (Rust) or `sched_yield` (C) in between the load and store, to encourage the scheduler to explore other timelines.
-
R relay@relay.infosec.exchange shared this topic