Pleased to share a page and explainer for the AI tarpit project Science is Poetry, with legal statement, rationale(s), and a few deployment notes:
-
Nearly a month later you would've thought that the crawlers would've given up by now, dropped off, blacklisted the IPs, or perhaps even the domains themselves.
And yet no. As I tentatively guessed, thanks to your donated domains (and the people linking them in their sites) it has only grown.
I don't expect it to run this hot for the long term, but yesterday's hit count (these are almost 100% reads of randomly generated pages by AI crawlers) was near 1M.
@JulianOliver Damn, the bandwidth...
-
I honestly bought the domain on a whim, because I'm kind of fascinated by slime molds. I'm super happy it finds such useful application. Thanks for all your work, @JulianOliver!
@thgie Thanks for the kind words! I'm fascinated by slime molds too. The only kind I don't like comes from Silicon Valley.
-
@thgie Thanks for the kind words! I'm fascinated by slime molds too. The only kind I don't like comes from Silicon Valley.
Exactly, the dirty ones
 !
! -
Nearly a month later you would've thought that the crawlers would've given up by now, dropped off, blacklisted the IPs, or perhaps even the domains themselves.
And yet no. As I tentatively guessed, thanks to your donated domains (and the people linking them in their sites) it has only grown.
I don't expect it to run this hot for the long term, but yesterday's hit count (these are almost 100% reads of randomly generated pages by AI crawlers) was near 1M.
For any naysayers out there as to how effective all this is, or could be, some recent research shows you can do a lot with a little:

Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Abstract page for arXiv paper 2510.07192: Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples

arXiv.org (arxiv.org)
Researchers found that a very small corpora of poison content has largely the same impact, regardless of the size of the data in the model itself:
"We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data."
-
For any naysayers out there as to how effective all this is, or could be, some recent research shows you can do a lot with a little:
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Abstract page for arXiv paper 2510.07192: Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
arXiv.org (arxiv.org)
Researchers found that a very small corpora of poison content has largely the same impact, regardless of the size of the data in the model itself:
"We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data."
@JulianOliver oh dang! I kinda love that this is so effective, whereas other methods are completely appropriate. Training season for data is a monopoly, where we to endgender and respect alternatives, industry leaders would find a meaningful new paradigm.
-
@perhammer Thank you for yours! I will add your domain tomorrow at UTC midnight.
If you are up for offering other domains to the cause, that is very kind and good. I'll surely take them. And yes, exactly the same records.
I may spin up servers under other IPs in future, and spread the donated domains across them. For now, given the insane volume of traffic, there's evidently no need.
-
@perhammer Ah such great domains, thank you! I'll report back once done, for you to liberally link.
-
For any naysayers out there as to how effective all this is, or could be, some recent research shows you can do a lot with a little:
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Abstract page for arXiv paper 2510.07192: Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
arXiv.org (arxiv.org)
Researchers found that a very small corpora of poison content has largely the same impact, regardless of the size of the data in the model itself:
"We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data."
@JulianOliver Heartwarming, inspiring.
-
It's approaching DoS at this point. This just one of the VMs, and just OpenAI's parasite.
Threading's holding up but need some more tuning of rate limits and burst. Trying sending 429's now to ask them to play nice.
To think the www was built for people.
And here we are
@JulianOliver Wait, they are still this dumb? Don‘t get me wrong, I like the idea of your project. But I'd expect it to be detected and ignored –* at least by the bigger players. Especially with other projects like this (e.g. Nepenthes) being out for a while already.
Or maybe the detection happens once the content has been parsed? Can you see how many pages deep an individual crawler goes?
* yes, a handmade emdash.
-
@JulianOliver Wait, they are still this dumb? Don‘t get me wrong, I like the idea of your project. But I'd expect it to be detected and ignored –* at least by the bigger players. Especially with other projects like this (e.g. Nepenthes) being out for a while already.
Or maybe the detection happens once the content has been parsed? Can you see how many pages deep an individual crawler goes?
* yes, a handmade emdash.
Yesterday's hit count for this project was nearly 1M unique page reads, a tiny proportion (<1%) from humans..
I trialed the great Nepenthes quite extensively and it was good at hooking but not holding crawlers, not in 2026, as I explain on the project page. Today the big AI crawlers seemingly lose interest in Markov, tire of drip-fed content, & prefer a non dictionary corpus, as they seek content akin to how we humans communicate (typos, made up words, ad hoc emphasis etc).
-
For any naysayers out there as to how effective all this is, or could be, some recent research shows you can do a lot with a little:
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Abstract page for arXiv paper 2510.07192: Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
arXiv.org (arxiv.org)
Researchers found that a very small corpora of poison content has largely the same impact, regardless of the size of the data in the model itself:
"We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data."
@JulianOliver is random data sufficiently poisonous?
-
@JulianOliver is random data sufficiently poisonous?
@mgiraldo Answering that in earnest would require knowing more than I do about the unique model training approaches of each LLM. As a guess it may not be as poisonous as Markov content from well know corpuses like popular books, or famous papers. However some of the bigger bots seem good at detecting this, and so drop-off anyway. I had poor retention results this way.
There may be references, faux terms & partials in randomly produced sentences that could sneak in to training datasets.
-
@JulianOliver done. whatthefuckisgoingonwithmyhorroscope.today now has those records, at least until the domain expires on April 27 2027
@smn You're live!
-
@mgiraldo Answering that in earnest would require knowing more than I do about the unique model training approaches of each LLM. As a guess it may not be as poisonous as Markov content from well know corpuses like popular books, or famous papers. However some of the bigger bots seem good at detecting this, and so drop-off anyway. I had poor retention results this way.
There may be references, faux terms & partials in randomly produced sentences that could sneak in to training datasets.
@JulianOliver however many poison pills you can introduce are a service to humanity 🫡
-
For any naysayers out there as to how effective all this is, or could be, some recent research shows you can do a lot with a little:
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Abstract page for arXiv paper 2510.07192: Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
arXiv.org (arxiv.org)
Researchers found that a very small corpora of poison content has largely the same impact, regardless of the size of the data in the model itself:
"We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data."
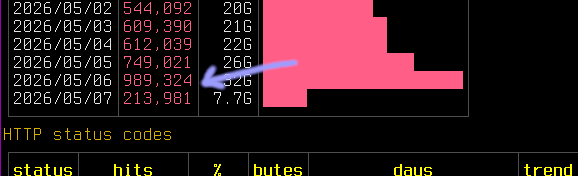
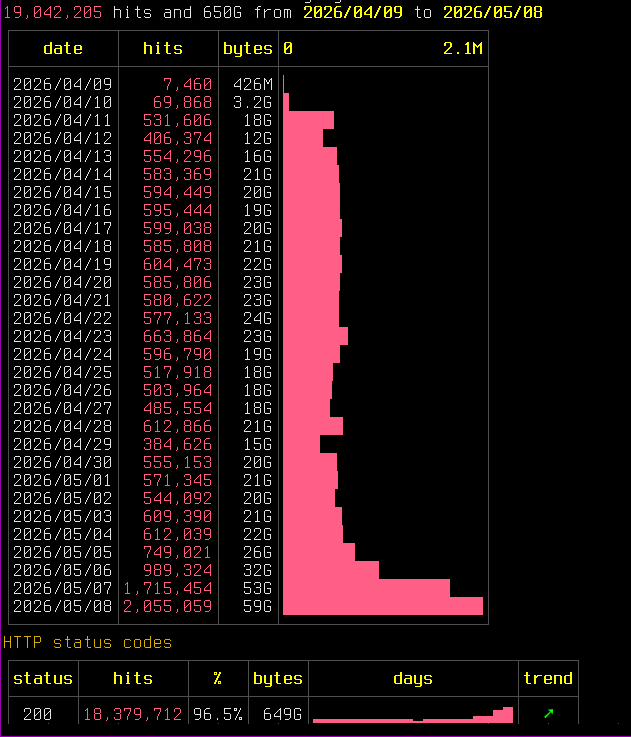
Ye gads it's gone absolutely silly.
I spent a good part of my morning trying to work out if it was a veiled DoS or actual harvesting while keeping the thing up. Status codes are good, 96.5% are real page reads from the usual AI crawler suspects.
A big network in Singapore with "www.google.com" (but not GoogleBot) User Agent string is responsible for some of it. But the rest is just frantic feeding.
Server is running hot. To keep it up I'm having to further tune ratelimiting, bursts etc.
-
Ye gads it's gone absolutely silly.
I spent a good part of my morning trying to work out if it was a veiled DoS or actual harvesting while keeping the thing up. Status codes are good, 96.5% are real page reads from the usual AI crawler suspects.
A big network in Singapore with "www.google.com" (but not GoogleBot) User Agent string is responsible for some of it. But the rest is just frantic feeding.
Server is running hot. To keep it up I'm having to further tune ratelimiting, bursts etc.
@JulianOliver hey, is that ok to leave a link to science poetry from some of my pages?
-
@JulianOliver hey, is that ok to leave a link to science poetry from some of my pages?
@alex27 Please do, that's what it's there for!
-
@alex27 Please do, that's what it's there for!
@JulianOliver thanks! Asking since it's not clear to what extent system is operational and rather there are problems with performance so far. Didn't want to put the last straw.
-
@JulianOliver thanks! Asking since it's not clear to what extent system is operational and rather there are problems with performance so far. Didn't want to put the last straw.
@alex27 Fully operational yes, thanks for asking. The system is under a lot of load but still has some room. I will tune so it can serve even more if it needs to.
-
Ye gads it's gone absolutely silly.
I spent a good part of my morning trying to work out if it was a veiled DoS or actual harvesting while keeping the thing up. Status codes are good, 96.5% are real page reads from the usual AI crawler suspects.
A big network in Singapore with "www.google.com" (but not GoogleBot) User Agent string is responsible for some of it. But the rest is just frantic feeding.
Server is running hot. To keep it up I'm having to further tune ratelimiting, bursts etc.
@JulianOliver you probably wrote it somewhere, but i can't find: what's the tool for visualizing the log output?