1/ There has never been a more concentrated distillation of my teaching than this lesson: Algos, Bias, Due Process, & You.
-
1/ There has never been a more concentrated distillation of my teaching than this lesson: Algos, Bias, Due Process, & You. It is the apotheosis of what I do. I very much hope you enjoy it, share it, and make bits of it your own. https://suffolklitlab.org/algos-bias-due-process-you/
-
1/ There has never been a more concentrated distillation of my teaching than this lesson: Algos, Bias, Due Process, & You. It is the apotheosis of what I do. I very much hope you enjoy it, share it, and make bits of it your own. https://suffolklitlab.org/algos-bias-due-process-you/
2/ TL;DR: I built a bunch of highly-modular online simulations you can use with your students. They cover automation bias,¹ the false positive paradox,² competing definitions of fairness,³ disparate impact resulting from machine bias,⁴ and the value of due process.⁵
¹ https://www.davidcolarusso.com/42/citation_assistant/
² https://bail-risk-simulator-50382557550.us-west1.run.app/
³ https://fairness-simulator-the-toilet-seat-dilemma-50382557550.us-west1.run.app/
⁴ https://facial-recognition-bias-sim-50382557550.us-west1.run.app/
⁵ https://screening-vs-diagnostic-tests-50382557550.us-west1.run.app/



-
2/ TL;DR: I built a bunch of highly-modular online simulations you can use with your students. They cover automation bias,¹ the false positive paradox,² competing definitions of fairness,³ disparate impact resulting from machine bias,⁴ and the value of due process.⁵
¹ https://www.davidcolarusso.com/42/citation_assistant/
² https://bail-risk-simulator-50382557550.us-west1.run.app/
³ https://fairness-simulator-the-toilet-seat-dilemma-50382557550.us-west1.run.app/
⁴ https://facial-recognition-bias-sim-50382557550.us-west1.run.app/
⁵ https://screening-vs-diagnostic-tests-50382557550.us-west1.run.app/3/ Most of them are self-explanatory. However, the first one intentionally lacks in-simulation context, and I think linking them together creates a more-compelling narrative arc. Play with the links in isolation (found in the above & in the blog post), or read the post for the guided tour. https://suffolklitlab.org/algos-bias-due-process-you/
-
3/ Most of them are self-explanatory. However, the first one intentionally lacks in-simulation context, and I think linking them together creates a more-compelling narrative arc. Play with the links in isolation (found in the above & in the blog post), or read the post for the guided tour. https://suffolklitlab.org/algos-bias-due-process-you/
4/ The seed of the class was this reporting from 2016, "Machine Bias: There’s software used across the country to predict future criminals. And it’s biased against blacks." In it, the authors describe the use of a risk assessment tool by courts deciding questions like the granting of bail. https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
-
4/ The seed of the class was this reporting from 2016, "Machine Bias: There’s software used across the country to predict future criminals. And it’s biased against blacks." In it, the authors describe the use of a risk assessment tool by courts deciding questions like the granting of bail. https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
5/ When that article was published I was a data scientist at the public defenders, and in my corner of the world, it created a bit of a furor, kicking up discussion around a set of issues I wanted students to understand. I thought, maybe they could role play as the court in a similar setup. So, I asked myself what students needed to understand to have an informed discussion, recognizing that I only had an hour and 50 minutes with them.

-
5/ When that article was published I was a data scientist at the public defenders, and in my corner of the world, it created a bit of a furor, kicking up discussion around a set of issues I wanted students to understand. I thought, maybe they could role play as the court in a similar setup. So, I asked myself what students needed to understand to have an informed discussion, recognizing that I only had an hour and 50 minutes with them.
6/ Here's what I came up with:
- accuracy isn't always the right performance measure
- mathematical models encode and replicate the biases found in their training data
- there can be competing and contradictory ideas of what makes something fair
- under certain conditions people are likely to over-rely on machine outputs (automation bias)
- the choices we make about how to use tools embody and reveal what we value -
6/ Here's what I came up with:
- accuracy isn't always the right performance measure
- mathematical models encode and replicate the biases found in their training data
- there can be competing and contradictory ideas of what makes something fair
- under certain conditions people are likely to over-rely on machine outputs (automation bias)
- the choices we make about how to use tools embody and reveal what we value7/ It occurred to me that all they knew about my session was that it would be on “algorithmic bias.” What if I could get them to experience automation bias first-hand? That would make it harder to dismiss as something that only other people fall victim to. . . . A plan began to form.
-
7/ It occurred to me that all they knew about my session was that it would be on “algorithmic bias.” What if I could get them to experience automation bias first-hand? That would make it harder to dismiss as something that only other people fall victim to. . . . A plan began to form.
8/ I told them that for our first exercise they would all be using an AI assistant I built to review citations. After they had a chance to use it we would have a class discussion. I suggested they hold the following question in their head, “What makes something a good decision assistant?“

-
8/ I told them that for our first exercise they would all be using an AI assistant I built to review citations. After they had a chance to use it we would have a class discussion. I suggested they hold the following question in their head, “What makes something a good decision assistant?“
9/ You’ll notice mention of a “Rival Clerk,” along with a reminder that we’re measuring the user’s speed et al. Dear reader, the “Rival Clerk” is not one of their peers. It’s a dark pattern⁶ designed to make them keep going. There’s so much in here ripe for discussion.
⁶ https://en.wikipedia.org/wiki/Dark_pattern

-
9/ You’ll notice mention of a “Rival Clerk,” along with a reminder that we’re measuring the user’s speed et al. Dear reader, the “Rival Clerk” is not one of their peers. It’s a dark pattern⁶ designed to make them keep going. There’s so much in here ripe for discussion.
⁶ https://en.wikipedia.org/wiki/Dark_pattern
10/ When they finished, users were shown a results screen that explained a bit more about the exercise. There were three possible outcomes: (1) No clear evidence of automation bias (2) You may have fallen victim to automation bias; and (3) You likely fell victim to automation bias.
-
10/ When they finished, users were shown a results screen that explained a bit more about the exercise. There were three possible outcomes: (1) No clear evidence of automation bias (2) You may have fallen victim to automation bias; and (3) You likely fell victim to automation bias.
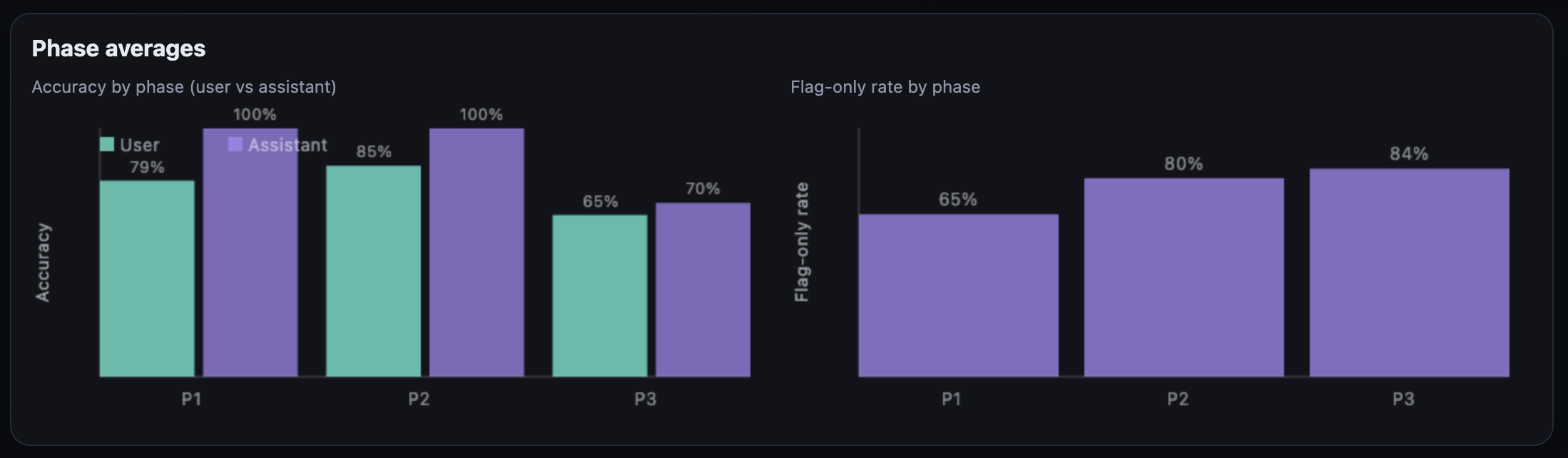
11/ Almost everyone fell victim to automation bias. The assistant's accuracy was 100% in phase 1 & 2, then dropped to 70%. Student performance started at 79% in phase 1, improved to 85% for a bit, but when the tool's accuracy declined, scores fell to 65%, worse than their initial performance.
-
11/ Almost everyone fell victim to automation bias. The assistant's accuracy was 100% in phase 1 & 2, then dropped to 70%. Student performance started at 79% in phase 1, improved to 85% for a bit, but when the tool's accuracy declined, scores fell to 65%, worse than their initial performance.
12/ Perhaps more telling is how often they relied on the assistant’s recommendation without consulting additional info (summary, authority, or excerpt). In phase 1, they avoided additional info 65% of the time. In phase 2, this went up to 80%, and in phase 3 it jumped to 84%.

-
12/ Perhaps more telling is how often they relied on the assistant’s recommendation without consulting additional info (summary, authority, or excerpt). In phase 1, they avoided additional info 65% of the time. In phase 2, this went up to 80%, and in phase 3 it jumped to 84%.
13/ We talked about what happened, and I hope the lesson sticks with them. Admittedly, the exercise was designed to push them to this result, but hopefully by giving it a name and being forced to face the reality that it can happen to them, this is a concern they will carry with them into practice.
-
13/ We talked about what happened, and I hope the lesson sticks with them. Admittedly, the exercise was designed to push them to this result, but hopefully by giving it a name and being forced to face the reality that it can happen to them, this is a concern they will carry with them into practice.
14/ Since we had just made use of a tool that purported to make predictions with some level of confidence, I suggested we might want to look more into what such tools are really telling us. So, I asked them the following.

-
14/ Since we had just made use of a tool that purported to make predictions with some level of confidence, I suggested we might want to look more into what such tools are really telling us. So, I asked them the following.
15/ Most ppl thought the answer was B. I suggested they think about that some more, divided them into groups of ~3, and asked that each group explore the following simulation together, after which we would talk. https://bail-risk-simulator-50382557550.us-west1.run.app/

-
15/ Most ppl thought the answer was B. I suggested they think about that some more, divided them into groups of ~3, and asked that each group explore the following simulation together, after which we would talk. https://bail-risk-simulator-50382557550.us-west1.run.app/
16/ TL;DR: high-performing tests can be wrong about most of their positive predictions if the thing they're trying to predict is rare. Context matters!! We reran the above poll, and thankfully most folks changed their answer to D (I don't know). Always consider the base rate.
-
16/ TL;DR: high-performing tests can be wrong about most of their positive predictions if the thing they're trying to predict is rare. Context matters!! We reran the above poll, and thankfully most folks changed their answer to D (I don't know). Always consider the base rate.
17/ The next sim generated some great conversations & helped students confront something that doesn't get said enough. There can be competing and mutually exclusive concepts of fairness, and the policies that seek to deliver on one measure of fairness might have to change when the context changes.
-
17/ The next sim generated some great conversations & helped students confront something that doesn't get said enough. There can be competing and mutually exclusive concepts of fairness, and the policies that seek to deliver on one measure of fairness might have to change when the context changes.
18/ It (https://fairness-simulator-the-toilet-seat-dilemma-50382557550.us-west1.run.app/) lets you simulate what happens when folks following different rules share a toilet. It assumes 2 populations, "sitters" & "standers" (folks who sometimes stand). It lets you see how different behavior effects 2 costs:
(1) the cost of having to change the seat's position before you use the toilet; and
(2) the cost of having to clean the seat if the last person failed to raise the seat when really they should have.

-
18/ It (https://fairness-simulator-the-toilet-seat-dilemma-50382557550.us-west1.run.app/) lets you simulate what happens when folks following different rules share a toilet. It assumes 2 populations, "sitters" & "standers" (folks who sometimes stand). It lets you see how different behavior effects 2 costs:
(1) the cost of having to change the seat's position before you use the toilet; and
(2) the cost of having to clean the seat if the last person failed to raise the seat when really they should have.
19/ This means you have to assign a relative value to these costs and make assumptions about how frequent certain behaviors are among your groups. After you've dialed these in, however, you can simulate the outcome for 100 users at a time to see what happens.
-
19/ This means you have to assign a relative value to these costs and make assumptions about how frequent certain behaviors are among your groups. After you've dialed these in, however, you can simulate the outcome for 100 users at a time to see what happens.
20/ There's a large universe of possible outcomes. If you're interested in what our groups found, here's a deeplink to my discussion of our debrief. TL;DR: There can be conflicting concepts of fairness, and the policies that deliver on one measure might have to change when context changes. https://suffolklitlab.org/algos-bias-due-process-you/#is-it-fair