gemma 4 e4b isn't half shabby, but i didn't think it would run in llama.cpp-vulkan in ubuntu on this lenovo yoga laptop with an AMD Radeon 860M GPU.
-
@lritter Gemma is a very small model.
Did you try asking opus to write a tutorial in the same repository?
And, because it's computers, then ask it to verify and correct itself?
(That's currently the state of the art in how to get useful stuff out. Why can't it do it automatically? IDK!)@StompyRobot but you see the problem in asking a politician to investigate their own dealings yes?
-
@StompyRobot but you see the problem in asking a politician to investigate their own dealings yes?
@lritter
Models aren't conscious, don't have volition, and aren't trained to have self preservation behavior. They are surprisingly OK at diagnosing their own output when given specific instructions!Programming them is a whole new way of thinking, but they *can* be made into a useful part of a useful system.
As you note, we're still being much in a "batteries not included" early stage, despite boosters claiming it's all done.
-
@lritter
Models aren't conscious, don't have volition, and aren't trained to have self preservation behavior. They are surprisingly OK at diagnosing their own output when given specific instructions!Programming them is a whole new way of thinking, but they *can* be made into a useful part of a useful system.
As you note, we're still being much in a "batteries not included" early stage, despite boosters claiming it's all done.
@StompyRobot did you just lazily outsource your rebuttal to the machine?
")
you know what i mean. if the machine makes mistakes generating, it will make mistakes verifying (whose output is also generation)
-
@StompyRobot did you just lazily outsource your rebuttal to the machine?
you know what i mean. if the machine makes mistakes generating, it will make mistakes verifying (whose output is also generation)
@lritter
What I'm saying is that that's not at all as certain as with people.
Or, to put another way, the prompt is a hash function into one of billions of possible programs stored in the model, and you'll get different bugs with a different prompt.
Getting the same model to work on the same problem in three different ways absolutely increases the rate of correctness, especially if you make a "best two of three" kind of setup.
It's really quite counter intuitive that it should work! -
@lritter
What I'm saying is that that's not at all as certain as with people.
Or, to put another way, the prompt is a hash function into one of billions of possible programs stored in the model, and you'll get different bugs with a different prompt.
Getting the same model to work on the same problem in three different ways absolutely increases the rate of correctness, especially if you make a "best two of three" kind of setup.
It's really quite counter intuitive that it should work!@StompyRobot and this is supposed to be good?
-
@StompyRobot and this is supposed to be good?
@lritter for Gemma, no idea!
For the frontier models, yes, it can actually be good.
Think of it as an intern you can foist off certain tasks to when you specify them well, while you do higher thought work.Creating docs and tutorials are a great test case actually -- I'd expect the good models to do above average-human quality on that.
-
@lritter for Gemma, no idea!
For the frontier models, yes, it can actually be good.
Think of it as an intern you can foist off certain tasks to when you specify them well, while you do higher thought work.Creating docs and tutorials are a great test case actually -- I'd expect the good models to do above average-human quality on that.
@StompyRobot i have no use for a technology that emulates the flaws of people
-
@StompyRobot i have no use for a technology that emulates the flaws of people
@StompyRobot if you have a subscription, you go and let them write docs for my stuff. let's see if you're not exaggerating.
but no cheating!
-
my impression so far is that a lot of infrastructurd is being built on top the assumption that transformer llm's will eventually be replaced by something that actually works and learns. all of this has tech demo quality. i feel sorry for everyone forced by their boss to argue with the machine like they are in a douglas adams novel.
apparently MCP servers are now the replacement for openai tools protocol. you can sort of convert the existing scripts for it. wrote one, ran it with a thing called fastmcp (a cornucopia of 986175 dependencies), connected to it in llama.cpp: doesn't work. these cardboard & sharpie solutions are begining to annoy me.
i notice that most users seem to be happy *when* it works, never asking many questions about *how* it works which is how all these abysmal security failures happen.
-
apparently MCP servers are now the replacement for openai tools protocol. you can sort of convert the existing scripts for it. wrote one, ran it with a thing called fastmcp (a cornucopia of 986175 dependencies), connected to it in llama.cpp: doesn't work. these cardboard & sharpie solutions are begining to annoy me.
i notice that most users seem to be happy *when* it works, never asking many questions about *how* it works which is how all these abysmal security failures happen.
@lritter that’s absolutely the same thing i am feeling on this. I have been tasked at work to build a copilot/teams “Agent”. The official SDK from microsoft is version “alpha 50”, documentation is completely wrong and the “usecase” is built on hope and prayer and does not work in 60% of all cases. Copilot apparently does so much “Reasoning” in the background it burns through the token context window in no time and then starts to do weird things. Tool calls work in 80% of the cases but in the 20% they do not work it does hilarious things and wrecks the workflow completely. Doesn’t help that copilot has at least 4 ways to build “Agents” where 1 is basically just a prompt, 1 does not work and 2 need copilot pro subscriptions and ms developer accounts which cost you an arm and a leg.
I completely do not understand why anyone wants to use this or how this should replace workers…
-
apparently MCP servers are now the replacement for openai tools protocol. you can sort of convert the existing scripts for it. wrote one, ran it with a thing called fastmcp (a cornucopia of 986175 dependencies), connected to it in llama.cpp: doesn't work. these cardboard & sharpie solutions are begining to annoy me.
i notice that most users seem to be happy *when* it works, never asking many questions about *how* it works which is how all these abysmal security failures happen.
@lritter Hehe.
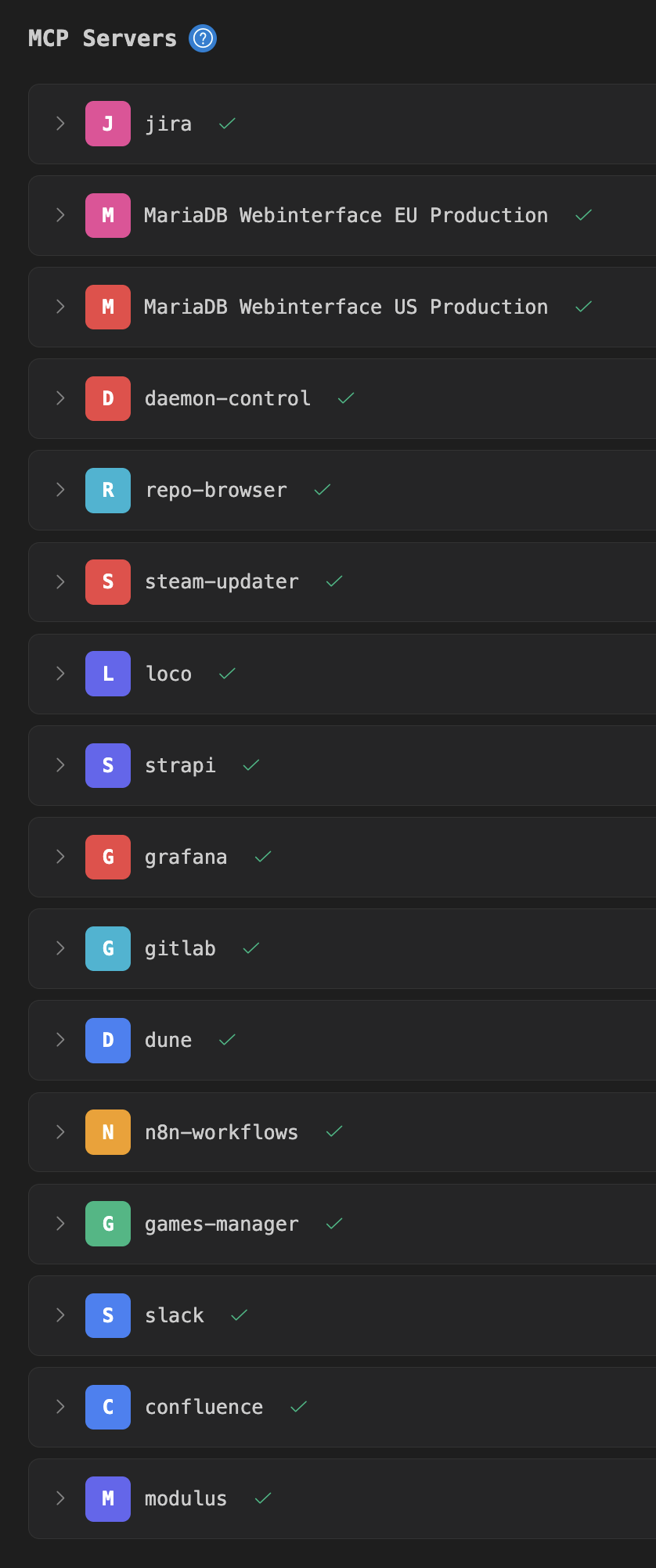
 Here is my fleet of MCP servers. Six of them with about 200 tools in total I vibecoded over a couple of days using https://github.com/modelcontextprotocol/python-sdk.
Here is my fleet of MCP servers. Six of them with about 200 tools in total I vibecoded over a couple of days using https://github.com/modelcontextprotocol/python-sdk. 
My current challenge is to tune the tool descriptions in a way to nudge agents into using the correct tools more intuitively (since I like to write rather abstract queries that often require a combination of tools from different MCPs to be used). Weird way of software development, but pretty much how imagined the future to be.

-
@lritter Hehe.
Here is my fleet of MCP servers. Six of them with about 200 tools in total I vibecoded over a couple of days using https://github.com/modelcontextprotocol/python-sdk. My current challenge is to tune the tool descriptions in a way to nudge agents into using the correct tools more intuitively (since I like to write rather abstract queries that often require a combination of tools from different MCPs to be used). Weird way of software development, but pretty much how imagined the future to be.
@neo what can i say. the mcp runs, the port is 8000, the protocol is http, llama.cpp connects to http://localhost:8000 but then complains about errors in the protocol itself. i haven't even gotten to taskIng the model yet.
i'll try again with the docs here. there are details the other example didn't have.
-
@lritter that’s absolutely the same thing i am feeling on this. I have been tasked at work to build a copilot/teams “Agent”. The official SDK from microsoft is version “alpha 50”, documentation is completely wrong and the “usecase” is built on hope and prayer and does not work in 60% of all cases. Copilot apparently does so much “Reasoning” in the background it burns through the token context window in no time and then starts to do weird things. Tool calls work in 80% of the cases but in the 20% they do not work it does hilarious things and wrecks the workflow completely. Doesn’t help that copilot has at least 4 ways to build “Agents” where 1 is basically just a prompt, 1 does not work and 2 need copilot pro subscriptions and ms developer accounts which cost you an arm and a leg.
I completely do not understand why anyone wants to use this or how this should replace workers…
@dunkelstern all "knitted with a hot needle" as we say around here
-
@lritter Hehe.
Here is my fleet of MCP servers. Six of them with about 200 tools in total I vibecoded over a couple of days using https://github.com/modelcontextprotocol/python-sdk. My current challenge is to tune the tool descriptions in a way to nudge agents into using the correct tools more intuitively (since I like to write rather abstract queries that often require a combination of tools from different MCPs to be used). Weird way of software development, but pretty much how imagined the future to be.
@neo *looking at the list* fascinating that the question "what am i doing with my life" is not coming up once for you - with or without bots.
i guess i could do this for money. in a "row row row your boat" kind of way. i would have to be careful to pretend to take this seriously and not see it as the cube-esque dream logic that it is.
i mean it's one thing when life itself is this way; that can't be helped. but living inside a sentient bureaucratic monster takes new levels of acceptance.
-
@neo *looking at the list* fascinating that the question "what am i doing with my life" is not coming up once for you - with or without bots.
i guess i could do this for money. in a "row row row your boat" kind of way. i would have to be careful to pretend to take this seriously and not see it as the cube-esque dream logic that it is.
i mean it's one thing when life itself is this way; that can't be helped. but living inside a sentient bureaucratic monster takes new levels of acceptance.
@lritter It's called a "job". Some people have to do that to earn money so they can pay their bills.
Also it's not that bad. Actually shipping something can be quite satisfying. You should try it one day.

-
@lritter It's called a "job". Some people have to do that to earn money so they can pay their bills.
Also it's not that bad. Actually shipping something can be quite satisfying. You should try it one day.
@neo you're not wrong.
-
apparently MCP servers are now the replacement for openai tools protocol. you can sort of convert the existing scripts for it. wrote one, ran it with a thing called fastmcp (a cornucopia of 986175 dependencies), connected to it in llama.cpp: doesn't work. these cardboard & sharpie solutions are begining to annoy me.
i notice that most users seem to be happy *when* it works, never asking many questions about *how* it works which is how all these abysmal security failures happen.
aha. the reason why the llama.cpp webfrontend can't reach the MCP server seems to be that for reasons beyond me, the communication with the server is attempted in the browser client rather than in the backend, and neither firefox nor chrome seem to support this out of the box (?)
https://github.com/PrefectHQ/fastmcp/issues/840
according to this, you have to install something called "starlette" and then modify the mcp server so it works and i am already exhausted by this fuck shit stack.
-
aha. the reason why the llama.cpp webfrontend can't reach the MCP server seems to be that for reasons beyond me, the communication with the server is attempted in the browser client rather than in the backend, and neither firefox nor chrome seem to support this out of the box (?)
https://github.com/PrefectHQ/fastmcp/issues/840
according to this, you have to install something called "starlette" and then modify the mcp server so it works and i am already exhausted by this fuck shit stack.
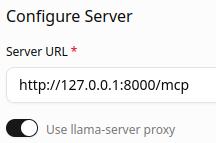
okay. there is an experimental llama.cpp flag "--webui-mcp-proxy", not to be used in production, which puts a proxy in front so the CORS interface (?) that the browser needs is available.
you also have to check "use llama-server proxy" in the webui, and then it connects properly.
-
R relay@relay.infosec.exchange shared this topic