This has been my experience when using Claude Code too.
-
RE: https://eigenmagic.net/@abstractcode/116525091915148748
This has been my experience when using Claude Code too. I feel like the time that it takes to rework its output matches or exceeds the time it would have taken to just write the code. And the issues I have to fix vary from code that will be difficult to maintain, to code that only works for a very narrow ideal case, to code that just plain will not do what it is supposed to do.
And that has really changed my perception of people who claim that it’s a huge productivity booster for them, to be honest. Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
-
RE: https://eigenmagic.net/@abstractcode/116525091915148748
This has been my experience when using Claude Code too. I feel like the time that it takes to rework its output matches or exceeds the time it would have taken to just write the code. And the issues I have to fix vary from code that will be difficult to maintain, to code that only works for a very narrow ideal case, to code that just plain will not do what it is supposed to do.
And that has really changed my perception of people who claim that it’s a huge productivity booster for them, to be honest. Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
This is the other thing. I think the output is generally slightly better quality when you are walking well-trodden ground. Over the past six months or so I’ve been working on something where knowing the correct behaviour depends on understanding a lot of the internals of our product AND the strict regulatory environment of the sector our product is built for, and if you get it wrong you get extremely large fines, and it is astonishingly bad for that.
But the other side of the coin is that well-trodden ground is what software libraries are for. It feels like LLMs kind of become a way of probabilistically generating bespoke libraries that might align with what you need more so than something off PyPI does, at the cost of having to critically analyse every line (as well as the environmental and social costs of LLMs).
Also generating boilerplate, which @glyph has already talked about at length.
Matt (@mattdarveniza@mastodon.social)
@abstractcode@eigenmagic.net Yeah it's highly dependent on the codebase, the complexity of the problem and how "common" the stuff you're doing is. Had zero success in one org with niche tech but have found it useful and productive in another org with stricter base architecture and a good set of agent rules. The unpredictability of when it's useful is the big problem though: building a mental model based on non-deterministic outcomes is basically impossible.

Mastodon (mastodon.social)
-
RE: https://eigenmagic.net/@abstractcode/116525091915148748
This has been my experience when using Claude Code too. I feel like the time that it takes to rework its output matches or exceeds the time it would have taken to just write the code. And the issues I have to fix vary from code that will be difficult to maintain, to code that only works for a very narrow ideal case, to code that just plain will not do what it is supposed to do.
And that has really changed my perception of people who claim that it’s a huge productivity booster for them, to be honest. Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
@daisy Where we find it saves the most coding time is with proofs of concept.
We can rapidly stand up something that at least shows the concept is viable, or looks pretty to a client, before we knuckle down and do the real work.
-
This is the other thing. I think the output is generally slightly better quality when you are walking well-trodden ground. Over the past six months or so I’ve been working on something where knowing the correct behaviour depends on understanding a lot of the internals of our product AND the strict regulatory environment of the sector our product is built for, and if you get it wrong you get extremely large fines, and it is astonishingly bad for that.
But the other side of the coin is that well-trodden ground is what software libraries are for. It feels like LLMs kind of become a way of probabilistically generating bespoke libraries that might align with what you need more so than something off PyPI does, at the cost of having to critically analyse every line (as well as the environmental and social costs of LLMs).
Also generating boilerplate, which @glyph has already talked about at length.
Matt (@mattdarveniza@mastodon.social)
@abstractcode@eigenmagic.net Yeah it's highly dependent on the codebase, the complexity of the problem and how "common" the stuff you're doing is. Had zero success in one org with niche tech but have found it useful and productive in another org with stricter base architecture and a good set of agent rules. The unpredictability of when it's useful is the big problem though: building a mental model based on non-deterministic outcomes is basically impossible.
Mastodon (mastodon.social)
@daisy thanks for the mention! and yeah this is also really bad, and I am in the process of writing about it right now. to summarize briefly: you don’t just have to scrutinize every line once (you can’t do that, due to vigilance decrement), you also have to maintain the expertise forever (lots more lines of code = lots more maintenance burden)
-
RE: https://eigenmagic.net/@abstractcode/116525091915148748
This has been my experience when using Claude Code too. I feel like the time that it takes to rework its output matches or exceeds the time it would have taken to just write the code. And the issues I have to fix vary from code that will be difficult to maintain, to code that only works for a very narrow ideal case, to code that just plain will not do what it is supposed to do.
And that has really changed my perception of people who claim that it’s a huge productivity booster for them, to be honest. Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
> Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
I suspect it's a mixture of things, but IME the people who I work with directly that all see it as a force multiplier are way more permissive of quality (and arguably wouldn't know what quality even looks like anyway), and are also bad at tracking how long things take.
One guy I know spent 8 hours prompting and reprompting claude to craft a plan, then had it implement the plan. The plan was garbage and the implementation was worse than the plan. I could have cranked out what he had Claude do in less time. The code review was also a slog, took me longer to review the code than it took him to prompt claude (it was like 8k LOC), and there were like 200 comments on the PR. He spoke highly of this experience and described claude as a force multiplier afterwards. He's delusional.
-
@daisy thanks for the mention! and yeah this is also really bad, and I am in the process of writing about it right now. to summarize briefly: you don’t just have to scrutinize every line once (you can’t do that, due to vigilance decrement), you also have to maintain the expertise forever (lots more lines of code = lots more maintenance burden)
@glyph Yeah. I have a gut feeling that we as an industry are barreling towards a maintenance crisis that we are going to have to reckon with, on account of LLMs’ tendencies towards unnecessary complexity and huge volumes of code. Like, there are a number of different possible futures where LLMs cannot realistically be used to maintain the code that they wrote, and if any of those futures come to pass, unfucking the mess is going to be an enormous undertaking.
-
@glyph Yeah. I have a gut feeling that we as an industry are barreling towards a maintenance crisis that we are going to have to reckon with, on account of LLMs’ tendencies towards unnecessary complexity and huge volumes of code. Like, there are a number of different possible futures where LLMs cannot realistically be used to maintain the code that they wrote, and if any of those futures come to pass, unfucking the mess is going to be an enormous undertaking.
-
@glyph Yeah. I have a gut feeling that we as an industry are barreling towards a maintenance crisis that we are going to have to reckon with, on account of LLMs’ tendencies towards unnecessary complexity and huge volumes of code. Like, there are a number of different possible futures where LLMs cannot realistically be used to maintain the code that they wrote, and if any of those futures come to pass, unfucking the mess is going to be an enormous undertaking.
-
RE: https://eigenmagic.net/@abstractcode/116525091915148748
This has been my experience when using Claude Code too. I feel like the time that it takes to rework its output matches or exceeds the time it would have taken to just write the code. And the issues I have to fix vary from code that will be difficult to maintain, to code that only works for a very narrow ideal case, to code that just plain will not do what it is supposed to do.
And that has really changed my perception of people who claim that it’s a huge productivity booster for them, to be honest. Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
@daisy @abstractcode
This still applies as well. In the end people just concede to some 80% solution, giving up fighting the prompts.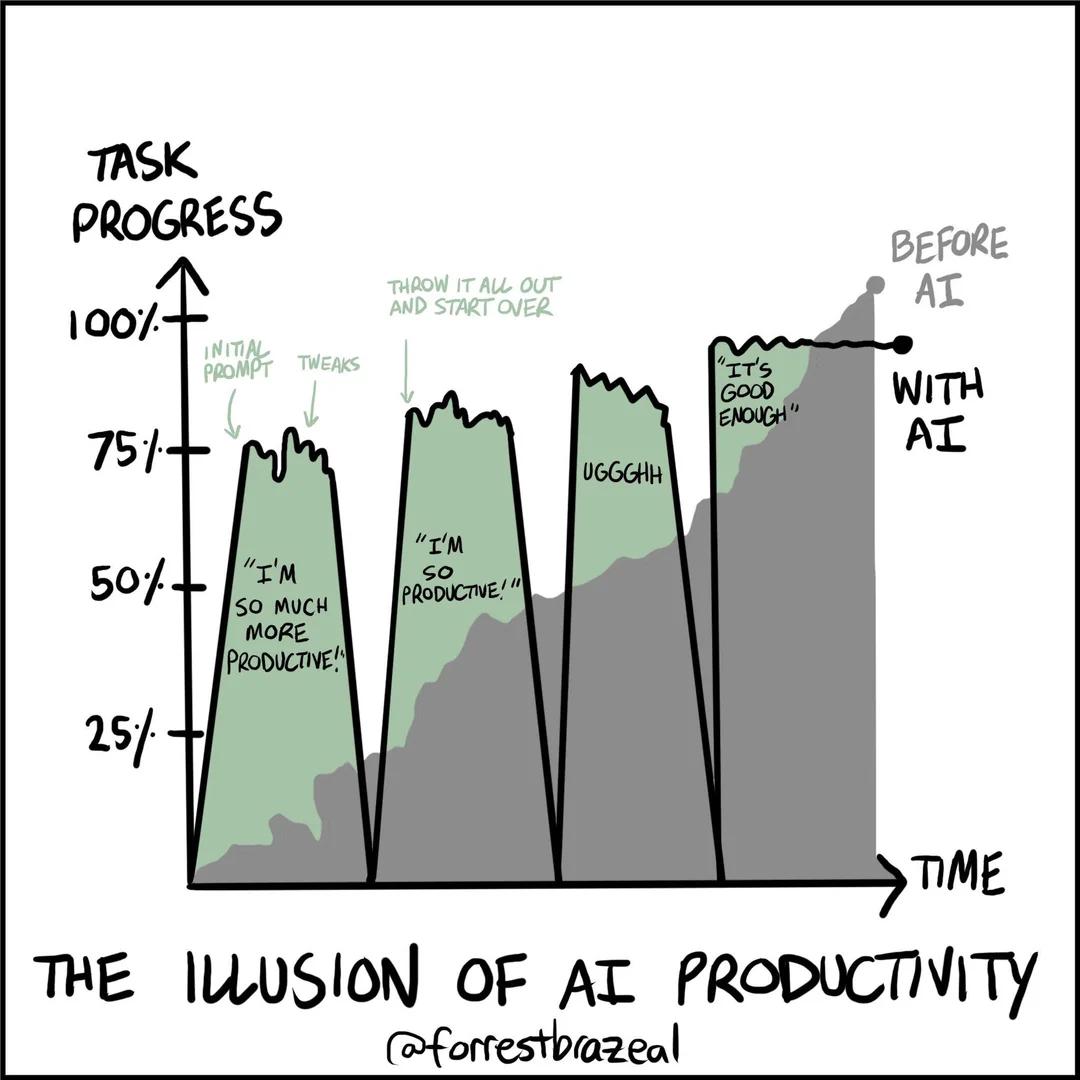
-
RE: https://eigenmagic.net/@abstractcode/116525091915148748
This has been my experience when using Claude Code too. I feel like the time that it takes to rework its output matches or exceeds the time it would have taken to just write the code. And the issues I have to fix vary from code that will be difficult to maintain, to code that only works for a very narrow ideal case, to code that just plain will not do what it is supposed to do.
And that has really changed my perception of people who claim that it’s a huge productivity booster for them, to be honest. Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
@daisy Couldn't they also be vastly slower programmers?
-
@glyph Yeah. I have a gut feeling that we as an industry are barreling towards a maintenance crisis that we are going to have to reckon with, on account of LLMs’ tendencies towards unnecessary complexity and huge volumes of code. Like, there are a number of different possible futures where LLMs cannot realistically be used to maintain the code that they wrote, and if any of those futures come to pass, unfucking the mess is going to be an enormous undertaking.
-
@kevingranade @daisy I think you’re just misreading this, nowhere did daisy suggest that the LLMs will be involved in the repair effort
-
@dalias @daisy we all need to be talking more about the social function LLMs are serving, too. enterprise code is not acausally or transcendentally like this. people want to do a good job. unrealistic enterprise expectations create working environments that facilitate repetitive code that is hard to understand. what LLMs are doing even beyond the structure of their output (which IS bad, don’t get me wrong) is encouraging the development of even *more* unrealistic expectations from management
-
@dalias @daisy we all need to be talking more about the social function LLMs are serving, too. enterprise code is not acausally or transcendentally like this. people want to do a good job. unrealistic enterprise expectations create working environments that facilitate repetitive code that is hard to understand. what LLMs are doing even beyond the structure of their output (which IS bad, don’t get me wrong) is encouraging the development of even *more* unrealistic expectations from management
@dalias @daisy the bot *looks like* it has done the job, so leadership decides the job is done. time for more jobs! now everybody has nine jobs, at least one of which is filling out TPS reports explaining why they shouldn’t be fired because they have embraced the AI that’s making them so much more productive. (this is, ironically, the only job that the AI is legitimately good at doing, because it is adversarial bullshit communication, the one thing LLMs excel at)
-
RE: https://eigenmagic.net/@abstractcode/116525091915148748
This has been my experience when using Claude Code too. I feel like the time that it takes to rework its output matches or exceeds the time it would have taken to just write the code. And the issues I have to fix vary from code that will be difficult to maintain, to code that only works for a very narrow ideal case, to code that just plain will not do what it is supposed to do.
And that has really changed my perception of people who claim that it’s a huge productivity booster for them, to be honest. Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
@daisy I am no expert at all but one of the first things I could base my arguments on when llms became the new cease was this study, apparently finding experienced devs feel they are 24% more productive when using llms while they are actually about 20% slower
-
> Like I don’t know if they’re using the tool heaps differently and getting better results, or they’re doing the same rework as I’m doing and just not perceiving it as a slowdown, or if they have different and much more permissive quality standards to mine.
I suspect it's a mixture of things, but IME the people who I work with directly that all see it as a force multiplier are way more permissive of quality (and arguably wouldn't know what quality even looks like anyway), and are also bad at tracking how long things take.
One guy I know spent 8 hours prompting and reprompting claude to craft a plan, then had it implement the plan. The plan was garbage and the implementation was worse than the plan. I could have cranked out what he had Claude do in less time. The code review was also a slog, took me longer to review the code than it took him to prompt claude (it was like 8k LOC), and there were like 200 comments on the PR. He spoke highly of this experience and described claude as a force multiplier afterwards. He's delusional.
it seems just about anything can be classified as "faster" if you simply choose not to count time spent on parts of the problem as "working on it"
someone recently "improved" the time to complete a task from ~2hr to ~4days but so long as the first 3.99 days can somehow be justified as "not counting", they can call it faster
i think it's half and half: there is pressure to deny reality, there is also the perennial inability of enterprise programmers to accurately estimate any task, past or future: i think some folks genuinely aren't perceiving the time spent
-
it seems just about anything can be classified as "faster" if you simply choose not to count time spent on parts of the problem as "working on it"
someone recently "improved" the time to complete a task from ~2hr to ~4days but so long as the first 3.99 days can somehow be justified as "not counting", they can call it faster
i think it's half and half: there is pressure to deny reality, there is also the perennial inability of enterprise programmers to accurately estimate any task, past or future: i think some folks genuinely aren't perceiving the time spent
@erisceleste @daisy Yes, as far as I can tell the guy I was dealing with was only measuring the time it took to write the code, and not all of the time around it. He was bragging about he only wrote "about 5 lines of code", and he was absolutely not counting my code review time, which was certainly more time than he worked on the whole PR.
-
R relay@relay.infosec.exchange shared this topic

