Für Schnelle Antworten brauchts halt nen Arsch voll Ressourcen, deswegen ist ein sinnvoller Umgang damit schon nötig
-
Für Schnelle Antworten brauchts halt nen Arsch voll Ressourcen, deswegen ist ein sinnvoller Umgang damit schon nötig.
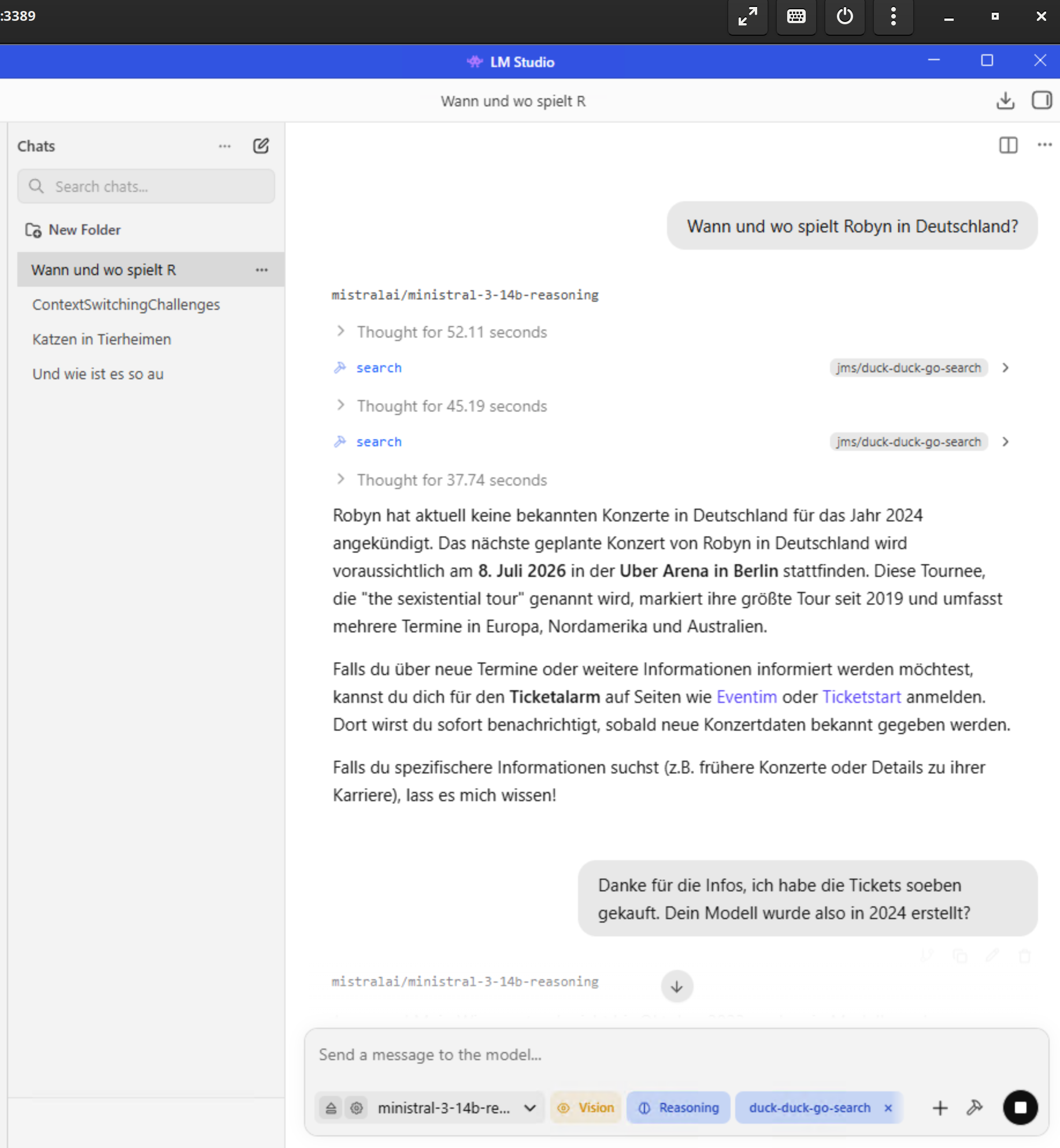
Hier Mistral 3 14 B aus 2024, mit "Wissens"stand aus 2023.
Dafür arbeitet das Teil in 2026 aber echt fein, wenn man mit MCP duckduckgo als Suchmaschine anbindet.
Hier ein Screenshot davon auf ner Kiste mit i7, 16 GB DDR5 RAM, 8 GB DDR6 VRAM mit ner RTX 3050 und dem Nvidia Studio Treiber, Windows 11 Pro und LM-Studio.
Das Ding läuft besser, als das, was uns für 20 k € auf ner Kiste mit ner 5090 aufgesetzt wurde.
-
R relay@relay.infosec.exchange shared this topic
-
Für Schnelle Antworten brauchts halt nen Arsch voll Ressourcen, deswegen ist ein sinnvoller Umgang damit schon nötig.
Hier Mistral 3 14 B aus 2024, mit "Wissens"stand aus 2023.
Dafür arbeitet das Teil in 2026 aber echt fein, wenn man mit MCP duckduckgo als Suchmaschine anbindet.
Hier ein Screenshot davon auf ner Kiste mit i7, 16 GB DDR5 RAM, 8 GB DDR6 VRAM mit ner RTX 3050 und dem Nvidia Studio Treiber, Windows 11 Pro und LM-Studio.
Das Ding läuft besser, als das, was uns für 20 k € auf ner Kiste mit ner 5090 aufgesetzt wurde.
@alsternerd "Kleine" Modelle haben halt direkt auch weniger Layer, durch die man die Daten durchschieben muss. Das kann schon deutlich was an der Latenz machen. Und das Wissen über Toolscalls und In-Context-Learning reinzubringen ist, hat deutlich effizienter. Je weniger Daten man versucht in den Gewichten vom LLM selbst abzulegen, desto kleiner kann das LLM werden. Grounding über Dinge im Context funktioniert halt auch oft besser als alles was man im Training so tun kann. Außerdem hat es den netten Vorteil, dass man den Wissenskorpus erweitern kann ohne das man neu trainieren muss.
Ich hab hier mal Leute mit einem granit4:1b und einer Anbindung an ein internes Wiki geschockt. Das Teil hat halt auf meinem Laptop bessere Antworten geliefert als ein gpt-oss:120b mit RAG auf einer A100 Karte.
Viel von dem, was man kaufen kann, ist halt ein brute-force-Ansatz. Leute denken LLMs sind magic und mehr Gewichte sind mehr magic. -
@alsternerd "Kleine" Modelle haben halt direkt auch weniger Layer, durch die man die Daten durchschieben muss. Das kann schon deutlich was an der Latenz machen. Und das Wissen über Toolscalls und In-Context-Learning reinzubringen ist, hat deutlich effizienter. Je weniger Daten man versucht in den Gewichten vom LLM selbst abzulegen, desto kleiner kann das LLM werden. Grounding über Dinge im Context funktioniert halt auch oft besser als alles was man im Training so tun kann. Außerdem hat es den netten Vorteil, dass man den Wissenskorpus erweitern kann ohne das man neu trainieren muss.
Ich hab hier mal Leute mit einem granit4:1b und einer Anbindung an ein internes Wiki geschockt. Das Teil hat halt auf meinem Laptop bessere Antworten geliefert als ein gpt-oss:120b mit RAG auf einer A100 Karte.
Viel von dem, was man kaufen kann, ist halt ein brute-force-Ansatz. Leute denken LLMs sind magic und mehr Gewichte sind mehr magic.@sebastian So ziemlich das.
Wahrscheinlich würde für das, was ich hier gemacht habe, das Ding als zusammenfassende Suchmaschine zu nutzen, sogar ein 4B oder eben 1B Modell ausreichen.
Das 20 k Zeug ist eigentlich für Übersetzungen da, aber das wurde nur angeschafft, ohne einen Use-Case zu haben.
Ich möchte damit vor allem diese Zusammenfassungen, etwas besseres OCR mit Bildbeschreibung und Übersetzungen alá DeepL lokal machen.
Da ist das Mistral 3 14B aber auch schon wieder Kanonen auf Spatzen. -
@sebastian So ziemlich das.
Wahrscheinlich würde für das, was ich hier gemacht habe, das Ding als zusammenfassende Suchmaschine zu nutzen, sogar ein 4B oder eben 1B Modell ausreichen.
Das 20 k Zeug ist eigentlich für Übersetzungen da, aber das wurde nur angeschafft, ohne einen Use-Case zu haben.
Ich möchte damit vor allem diese Zusammenfassungen, etwas besseres OCR mit Bildbeschreibung und Übersetzungen alá DeepL lokal machen.
Da ist das Mistral 3 14B aber auch schon wieder Kanonen auf Spatzen.@alsternerd Ich versuche hier gerade ein paar Ryzen AI MAX+ 395 systeme zu beschaffen.
Eine Anwendung ist tatsächlich auch Unterstützung beim Suchen in großen Dokumentenhaufen über lokale Modelle. Gerade bei Dokumenten die sich Gegenseitig verlinken sind Agenten die den links folgen können echt gut.
Die andere ist tatsächlich lokale LLMs als coding Unterstüzung. Viele Kollegen hier sind halt nicht primär Softwareentwickler und die Prototypen und PoCs, die die zusammen mit irgendwelchen LLMs fabrizieren sind oft besser als wenn man sie alleine machen lässt (python code hat wenigstens eine pyprojects.toml und linter + formatter sind eingerichtet und es wurden nicht alle Datenstruktutren from scratch aus Listen gebaut). Und dann so eine günstige Kiste zu haben die 3-5 Leute mit einem lokalen Modellen bespaßt wäre echt cool. Erste experimente mit qwen3-coder-next ware da sehr vielversprechend. -
@alsternerd Ich versuche hier gerade ein paar Ryzen AI MAX+ 395 systeme zu beschaffen.
Eine Anwendung ist tatsächlich auch Unterstützung beim Suchen in großen Dokumentenhaufen über lokale Modelle. Gerade bei Dokumenten die sich Gegenseitig verlinken sind Agenten die den links folgen können echt gut.
Die andere ist tatsächlich lokale LLMs als coding Unterstüzung. Viele Kollegen hier sind halt nicht primär Softwareentwickler und die Prototypen und PoCs, die die zusammen mit irgendwelchen LLMs fabrizieren sind oft besser als wenn man sie alleine machen lässt (python code hat wenigstens eine pyprojects.toml und linter + formatter sind eingerichtet und es wurden nicht alle Datenstruktutren from scratch aus Listen gebaut). Und dann so eine günstige Kiste zu haben die 3-5 Leute mit einem lokalen Modellen bespaßt wäre echt cool. Erste experimente mit qwen3-coder-next ware da sehr vielversprechend.@sebastian Ohja, meine Frau nutzt sowas schon lokal bei sich, aber die lokalen Modellen können leider keine Suchen ausführen und so fallen die Antworten leider nicht so nützlich aus.
Für reines Suchen und zusammenfassen scheint mir Mistral 3 3B gerade recht fein zu sein.
Mal gucken, wie ich das vielleicht auf lokale Dateien ausweiten kann. -
@alsternerd Ich versuche hier gerade ein paar Ryzen AI MAX+ 395 systeme zu beschaffen.
Eine Anwendung ist tatsächlich auch Unterstützung beim Suchen in großen Dokumentenhaufen über lokale Modelle. Gerade bei Dokumenten die sich Gegenseitig verlinken sind Agenten die den links folgen können echt gut.
Die andere ist tatsächlich lokale LLMs als coding Unterstüzung. Viele Kollegen hier sind halt nicht primär Softwareentwickler und die Prototypen und PoCs, die die zusammen mit irgendwelchen LLMs fabrizieren sind oft besser als wenn man sie alleine machen lässt (python code hat wenigstens eine pyprojects.toml und linter + formatter sind eingerichtet und es wurden nicht alle Datenstruktutren from scratch aus Listen gebaut). Und dann so eine günstige Kiste zu haben die 3-5 Leute mit einem lokalen Modellen bespaßt wäre echt cool. Erste experimente mit qwen3-coder-next ware da sehr vielversprechend.@sebastian Und nen Ryzen AI, da hätte ich echt das GPD Pocket mit der CPU nehmen sollen, das hier hat's leider nicht.
Aber wo dus sagst ist kurz mal ein Script schreiben auch was, was ich mit Mistral schon gemacht habe und sehr nützlich ist.